En esta semana continuamos con contrastes de hipótesis, enfocándonos en pruebas para comparar dos muestras independientes y pareadas, pruebas para igualdad de varianzas, y conceptos fundamentales de potencia estadística y cálculo de tamaño muestral.
Prueba Z para Diferencia de Medias (Varianzas Conocidas)
Hipótesis e Estadístico de Prueba
Consideramos las hipótesis:
- Bilateral: \(H_0: \mu_1 - \mu_2 = \omega_0\) vs. \(H_1: \mu_1 - \mu_2 \neq \omega_0\)
- Unilateral derecha: \(H_0: \mu_1 - \mu_2 \leq \omega_0\) vs. \(H_1: \mu_1 - \mu_2 > \omega_0\)
- Unilateral izquierda: \(H_0: \mu_1 - \mu_2 \geq \omega_0\) vs. \(H_1: \mu_1 - \mu_2 < \omega_0\)
(Habitualmente, \(\omega_0 = 0\))
Bajo \(H_0\) (asumiendo \(\omega = \omega_0\)):
\[Z = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}} \sim N(0, 1)\]
Criterios de rechazo: - Bilateral: Rechazo si \(|Z| > z_{1-\alpha/2}\) - Unilateral derecha: Rechazo si \(Z > z_{1-\alpha}\) - Unilateral izquierda: Rechazo si \(Z < -z_{1-\alpha}\)
Prueba t para Dos Muestras Independientes (Varianzas Desconocidas)
Caso 1: Varianzas Iguales (Homogéneas)
Cuando no conocemos las varianzas pero asumimos que son iguales (\(\sigma_1^2 = \sigma_2^2 = \sigma^2\)), utilizamos un estimador combinado (pooled) de la varianza:
\[S_p^2 = \frac{(n_1 - 1)S_1^2 + (n_2 - 1)S_2^2}{n_1 + n_2 - 2}\]
donde \(S_1^2\) y \(S_2^2\) son las varianzas muestrales sesgadas:
\[S_j^2 = \frac{1}{n_j - 1} \sum_{i=1}^{n_j} (X_{ji} - \bar{X}_j)^2, \quad j = 1, 2\]
El estimador de la varianza de la diferencia es:
\[S_D^2 = S_p^2 \left( \frac{1}{n_1} + \frac{1}{n_2} \right)\]
\[T = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{S_D} \sim t_{n_1 + n_2 - 2}\]
bajo \(H_0: \mu_1 - \mu_2 = \omega_0\).
Grados de libertad: \(\nu = n_1 + n_2 - 2\)
Criterios de rechazo: - Bilateral: Rechazo si \(|T| > t_{1-\alpha/2;\nu}\) - Unilateral derecha: Rechazo si \(T > t_{1-\alpha;\nu}\) - Unilateral izquierda: Rechazo si \(T < -t_{1-\alpha;\nu}\)
Caso 2: Varianzas Desiguales (Heterogéneas) — Prueba de Welch
Cuando las varianzas poblacionales son desiguales (\(\sigma_1^2 \neq \sigma_2^2\)), la solución es aproximada.
\[T = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}} \approx t_\nu\]
donde los grados de libertad aproximados (Welch-Satterthwaite) son:
\[\nu = \frac{\left( \frac{S_1^2}{n_1} + \frac{S_2^2}{n_2} \right)^2}{\frac{1}{n_1-1}\left(\frac{S_1^2}{n_1}\right)^2 + \frac{1}{n_2-1}\left(\frac{S_2^2}{n_2}\right)^2}\]
Este test es más conservador que asumir varianzas iguales.
Documentacion completa de las tres funciones en Sección B.5.
# t-test para 2 Muestras Independientes
# -------------------------------------
# Información muestral y estimación de las medias
Niveles de agrupación: Hombre, Mujer
n media dt sem IC
osteo$hba1c [Hombre] 45 8.55 1.745 0.260 (8.029, 9.078)
osteo$hba1c [Mujer] 49 8.58 1.864 0.266 (8.04, 9.111)
____
* IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
# Pruebas de normalidad (test de Shapiro-Wilk)
[1] Para grupo = Hombre, W = 0.958, gl = 45, p = 0.102
[2] Para grupo = Mujer, W = 0.980, gl = 49, p = 0.566
# Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
Fexp = 1.141, gl₁ = 48, gl₂ = 44, p = 0.660
# Diferencia de medias (osteo$hba1c [Mujer] - osteo$hba1c [Hombre])
Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
a) Test de Student (varianzas homogéneas)
texp = 0.059, gl = 92
p = 0.953 para la alternativa bilateral H₁:μ₁≠μ₂
p = 0.476 para la alternativa unilateral H₁:μ₁<μ₂
95%-IC(μ₂-μ₁) = (-0.719, 0.764)
b) Test de Welch (varianzas no homogéneas)
texp = 0.060, gl = 91.96
p = 0.953 para la alternativa bilateral H₁:μ₁≠μ₂
p = 0.476 para la alternativa unilateral H₁:μ₁<μ₂
95%-IC(μ₂-μ₁) = (-0.717, 0.762)
[[1]]
[1] 2.31
[[2]]
[1] 48
[[3]]
[1] 44
[[4]]
[1] 0.00585
Test de Wilcoxon/Mann-Whithney para dos muestras independientes
----------------------------------------------------------------
# Información muestral ---
Muestra n min Q1 Q2 Q3 max
1 osteo$imc[osteo$grupo_edad == "< 25"] 32 19.628 21.421 22.845 24.149 32.475
2 osteo$imc[osteo$grupo_edad == "> 33"] 30 18.070 23.382 25.889 28.945 37.333
RIQ
1 2.728
2 5.563
# Rangos ---
Muestra n Suma_rangos Rango_medio U
1 osteo$imc[osteo$grupo_edad == "< 25"] 32 807 25.219 681.000
2 osteo$imc[osteo$grupo_edad == "> 33"] 30 1146 38.200 279.000
# Test ---
U = 279.000; Z = 2.831; W = 279.000; p = 0.004
# Tamaño del efecto ---
Diferencia de localización: -2.668 95%-IC = (-4.518, -0.778)
r = 0.360 (criterio: 0.1 pequeño; 0.3 mediano; >0.5 grande)
Probabilidad de superioridad PS = 0.709
(probabilidad de que un valor al azar de M1 sea < a un valor al azar de M2)
Prueba F para Igualdad de Varianzas
Hipótesis y Estadístico
En algunos análisis necesitamos probar si dos varianzas poblacionales son iguales.
Consideramos:
- Bilateral: \(H_0: \sigma_1^2 = \sigma_2^2\) vs. \(H_1: \sigma_1^2 \neq \sigma_2^2\)
- Unilateral derecha: \(H_0: \sigma_1^2 \leq \sigma_2^2\) vs. \(H_1: \sigma_1^2 > \sigma_2^2\)
- Unilateral izquierda: \(H_0: \sigma_1^2 \geq \sigma_2^2\) vs. \(H_1: \sigma_1^2 < \sigma_2^2\)
Bajo \(H_0\) (\(\sigma_1^2 = \sigma_2^2\)):
\[F = \frac{S_1^2}{S_2^2} \sim F_{n_1-1, n_2-1}\]
Criterios de rechazo: - Bilateral: Rechazo si \(F < F_{n_1-1, n_2-1, \alpha/2}\) o \(F > F_{n_1-1, n_2-1, 1-\alpha/2}\) - Unilateral derecha: Rechazo si \(F > F_{n_1-1, n_2-1, 1-\alpha}\) - Unilateral izquierda: Rechazo si \(F < F_{n_1-1, n_2-1, \alpha}\)
No recomendamos realizar la prueba F antes de elegir entre test t con varianzas iguales o desiguales, porque esta prueba de igualdad consume el nivel de significancia global. Es preferir usar siempre la Prueba de Welch como default, que es válida en ambos casos.
Potencia de una Prueba
Conceptos Fundamentales
La potencia es un concepto crucial en el diseño y evaluación de estudios estadísticos.
La función de potencia \(G(\theta)\) es la probabilidad de rechazar \(H_0\) cuando el parámetro verdadero es \(\theta\):
\[G(\theta) = P(\text{rechazar } H_0 | \theta)\]
Interpretación: - Si \(\theta \in \Theta_0\) (región de \(H_0\)): \(G(\theta) = P(\text{Error Tipo I}) \leq \alpha\) - Si \(\theta \in \Theta_1\) (región de \(H_1\)): \(G(\theta) = P(\text{Rechazo correcto}) = 1 - \beta(\theta)\)
donde \(\beta(\theta)\) es la probabilidad del Error Tipo II.
Relación con Errores de Tipo I y II
| \(H_0\) es verdadera |
Error Tipo I (prob. \(\alpha\)) |
Decisión correcta |
| \(H_1\) es verdadera |
Decisión correcta (prob. \(1-\beta\)) |
Error Tipo II (prob. \(\beta\)) |
- Significancia (\(\alpha\)): Probabilidad de Error Tipo I. Típicamente 0.05.
- Potencia (\(1-\beta\)): Probabilidad de detectar una diferencia real. Típicamente 0.80 o 0.90.
Derivación: Potencia para Prueba Bilateral (Varianza Conocida)
Sea \(\mu_0\) el valor hipotetizado, \(\sigma\) conocida, tamaño muestral \(n\) y nivel de significancia \(\alpha\).
Para una prueba bilateral con \(H_0: \mu = \mu_0\) vs. \(H_1: \mu \neq \mu_0\):
\[G(\mu) = 1 - P\left(z_{1-\alpha/2} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}} \leq Z \leq z_{1-\alpha/2} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}}\right)\]
Equivalentemente:
\[G(\mu) = P\left(Z \leq -z_{1-\alpha/2} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}}\right) + P\left(Z > z_{1-\alpha/2} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}}\right)\]
Casos extremos: - En \(\mu = \mu_0\): \(G(\mu_0) = \alpha\) (tasa de Error Tipo I) - Conforme \(|\mu - \mu_0|\) aumenta: \(G(\mu) \to 1\) (potencia tiende a 1)
Potencia: Prueba Unilateral Derecha
Para \(H_0: \mu \leq \mu_0\) vs. \(H_1: \mu > \mu_0\):
\[G(\mu) = 1 - P\left(Z \leq z_{1-\alpha} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}}\right)\]
La potencia aumenta cuando \(\mu > \mu_0\), alcanzando su máximo cuando \(\mu\) es mucho mayor que \(\mu_0\).
Potencia: Prueba Unilateral Izquierda
Para \(H_0: \mu \geq \mu_0\) vs. \(H_1: \mu < \mu_0\):
\[G(\mu) = P\left(Z \leq -z_{1-\alpha} - \frac{\mu - \mu_0}{\sigma/\sqrt{n}}\right)\]
La potencia aumenta cuando \(\mu < \mu_0\), alcanzando su máximo cuando \(\mu\) es mucho menor que \(\mu_0\).
Factores que Afectan la Potencia
La potencia de una prueba depende de:
- Tamaño muestral (\(n\)): Aumentar \(n\) aumenta la potencia.
- Magnitud del efecto (\(|\mu - \mu_0|\) o \(\delta\)): Diferencias más grandes son más fáciles de detectar.
- Variabilidad (\(\sigma\)): Menor variabilidad aumenta la potencia.
- Nivel de significancia (\(\alpha\)): Aumentar \(\alpha\) aumenta la potencia, pero incrementa el Error Tipo I.
Potencia para Pruebas de Proporción
Cálculo de Tamaño Muestral
Principio General
El tamaño muestral se calcula especificando:
- Diferencia mínima relevante (\(\delta\)): Qué magnitud de efecto queremos detectar
- Nivel de significancia (\(\alpha\)): Típicamente 0.05
- Potencia deseada (\(1 - \beta\)): Típicamente 0.80 o 0.90
- Desviación estándar (\(\sigma\)): De estudios previos o piloto
Cálculo con BioEstatR: testt() y testp()
Las funciones testt() y testp() del paquete BioEstatR (ver Sección B.5) calculan simultáneamente el contraste de hipótesis, la potencia y el tamaño muestral necesario para detectar una diferencia mínima relevante \(\delta\) (effect size en unidades de la variable).
delta |
Diferencia mínima clínicamente relevante a detectar |
testt, testp |
potencia |
Potencia objetivo \(1-\beta\) (típicamente 0.80 o 0.90) |
testt, testp |
alfa |
Nivel de significancia \(\alpha\) (por defecto 0.05) |
testt, testp |
m, s, n |
Media, DT y tamaño piloto (estimaciones previas) |
testt |
x, n, p0 |
Éxitos, tamaño piloto y proporción hipotética |
testp |
Cuando se proporciona delta y potencia, la función devuelve el n necesario. Si en cambio se fija n y delta, devuelve la potencia alcanzada.
Dos escenarios reales del estudio piloto osteo (94 pacientes diabéticos):
- Contraste de medias (
testt): ¿Cuántos pacientes necesitamos para detectar una diferencia de \(\delta = 0.5\%\) en HbA1c respecto al umbral clínico de 7.5% con potencia del 90%?
- Contraste de proporciones (
testp): ¿Y para detectar una desviación de \(\delta = 0.05\) frente a una prevalencia hipotética de tabaquismo del 35% con potencia del 90%?
# t-Test con una muestra
# ----------------------
# Resumen de 'osteo$hba1c'
n = 94.000
media = 8.565
d.t. = 1.799
sem = 0.186
# Estimación de la media μ:
95%-IC(μ) = (8.196, 8.933)
# Test de normalidad de Shapiro-Wilk:
W = 0.983, gl = 94, p = 0.276
# Test de Student para contrastar H₀:μ=μ₀ con μ₀=7.500
texp = 5.740, gl = 93
p < 0.001 para la alternativa bilateral H₁:μ≠μ₀
p < 0.001 para la alternativa unilateral H₁:μ>μ₀
Estimación del efecto bruto
95%-IC(μ-μ₀) = (0.696, 1.433)
# Estudio de la potencia:
El test es significativo, se omite el análisis de la potencia.
# Test para contrastar una proporción binomial
# --------------------------------------------
# Información muestral
n = 94
x = 41 n-x=53
p = 0.436; q = (1-p) = 0.564
# Test Ho:π=0.350
[1] Método exacto
H1 Fexp Valor.p
Cola derecha π>0.350 1.410 0.052
Bilateral π≠0.350 - 0.103
95%-IC(π) = (0.339, 0.542) (método de Clooper-Pearson)
[2] Método aproximado a la distribución normal
Validez: min(nπ₀, n(1-π₀)) = 32.9 (>5, el método es válido)
zexp = 1.643, p = 0.100
95%-IC(π) = (0.335, 0.542) (método de Wilson)
# Tamaño de muestra para detectar |π-p₀|=δ
p₀ = 0.350; δ = 0.05
Casos (cpc = corrección por continuidad):
p1 n n_cpc
1 Unilateral π<0.350 0.300 753 773
2 Unilateral π>0.350 0.400 753 773
3 Bilateral π≠0.350 0.400 977 997
Los argumentos delta y potencia transforman un contraste de hipótesis estático (sólo p-valor) en un análisis prospectivo de diseño: cuantifican la sensibilidad del estudio para detectar efectos clínicamente relevantes. Para la HbA1c, el contraste resulta altamente significativo (\(t_{obs} = 5.74\), gl = 93, \(p < 0.001\)) por lo que testt() omite el análisis de potencia (la sensibilidad ya se confirma de facto sobre los \(n = 94\) pacientes actuales). Una desviación de medio punto porcentual respecto al umbral clínico (7.5%) corresponde a ~10–15 mg/dL de glucemia media, magnitud clínicamente relevante para decisiones terapéuticas. Para la prevalencia de tabaquismo, alcanzar potencia del 90% para detectar una desviación de 5 puntos porcentuales respecto al 35% hipotético exige n ≈ 977 pacientes (bilateral, ~997 con corrección por continuidad) o ≈ 753 (unilateral), aproximadamente diez veces el tamaño piloto. Esta asimetría refleja una propiedad clave: detectar diferencias en proporciones cercanas a 0.5 (varianza máxima \(p(1-p) = 0.25\)) consume más muestra que detectar diferencias en variables continuas con buen contraste señal/ruido. En el diseño de protocolos clínicos, este análisis previo evita el error de planificar estudios incapaces de detectar el efecto buscado (estudios negativos por falta de potencia, no por ausencia real de efecto), y constituye argumento obligado ante comités éticos y agencias financiadoras.
Comparación Múltiple y Corrección de Bonferroni
Problema: Inflación de Tasa de Error Tipo I
Cuando realizamos múltiples pruebas de hipótesis independientes con nivel \(\alpha\):
Si efectuamos \(k\) pruebas, la probabilidad de al menos un Error Tipo I es:
\[P(\text{al menos un Error Tipo I}) = 1 - (1 - \alpha)^k\]
Ejemplo: Con \(k = 10\) pruebas y \(\alpha = 0.05\):
\[P(\text{al menos un Error Tipo I}) = 1 - (0.95)^{10} \approx 0.401 = 40.1\%\]
En lugar del nivel de significancia global deseado del 5%, obtenemos una tasa de Error Tipo I del 40%!
Corrección de Bonferroni
Para mantener una tasa global de Error Tipo I de \(\alpha\) cuando realizamos \(k\) pruebas:
\[\alpha_{\text{ajustado}} = \frac{\alpha}{k}\]
Es decir, cada prueba individual se realiza con nivel de significancia \(\alpha/k\).
Ventajas: - Simple de implementar - Conservador (garantiza control del Error Tipo I)
Desventajas: - Muy conservador cuando \(k\) es grande - Reduce la potencia de cada prueba individual
Alternativas: El método de Holm, la corrección FDR (False Discovery Rate), o métodos Bayesianos son menos conservadores.
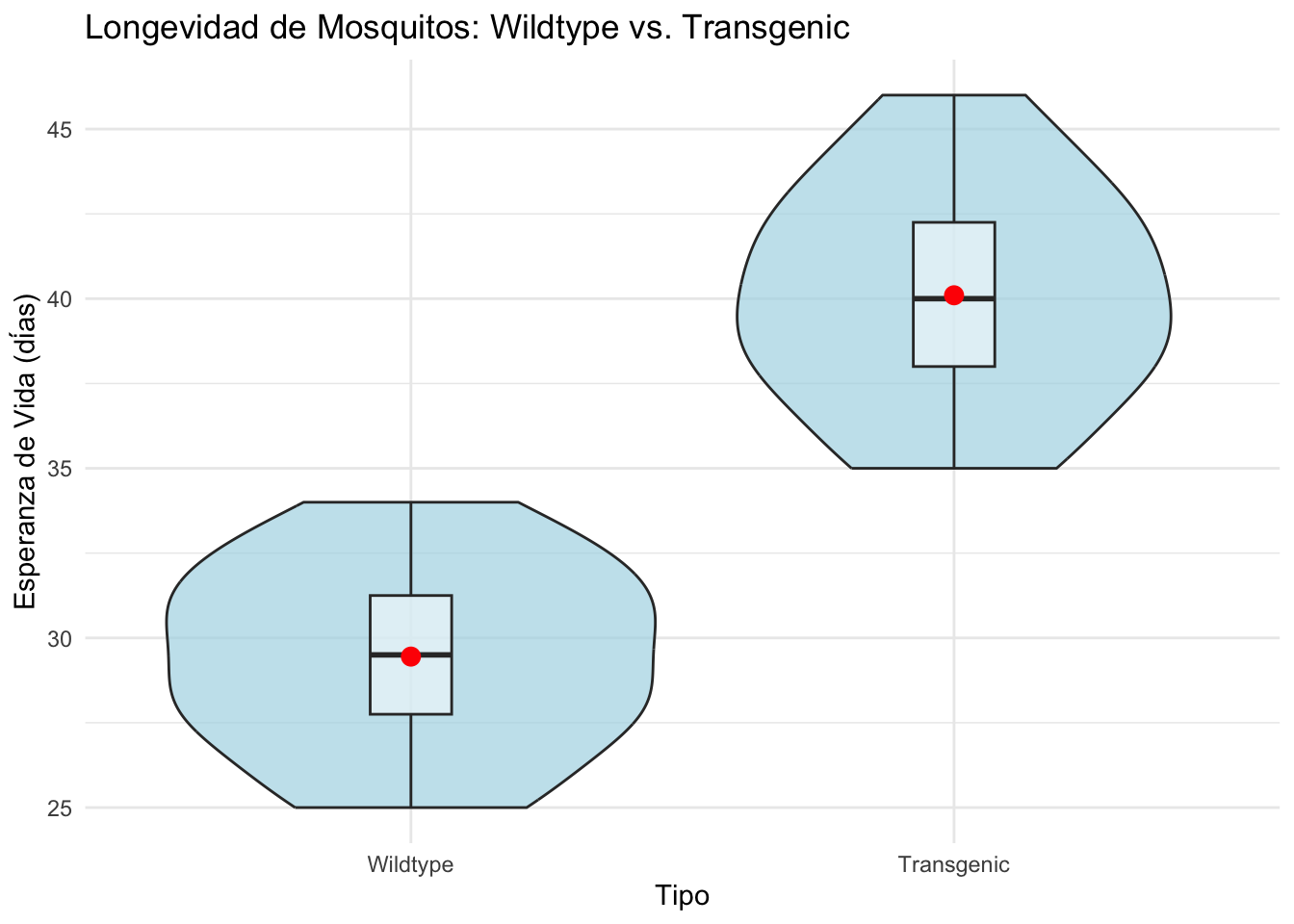
Ejemplo Completo: Análisis de Datos de Mosquitos
Contexto del Problema
Según la Organización Mundial de la Salud, los mosquitos Aedes pueden transmitir enfermedades como dengue y Zika. Un esfuerzo de control consiste en liberar mosquitos transgénicos con esperanza de vida más corta.
Pregunta de investigación: ¿Es la esperanza de vida significativamente diferente entre mosquitos salvajes (wildtype) y transgénicos?
Datos y Exploración
Wildtype: n = 20 , media = 29.4 , sd = 2.68
Transgenic: n = 20 , media = 40.1 , sd = 3.19
Test t: Varianzas Homogéneas
Primero suponemos varianzas iguales:
Two Sample t-test
data: wildtype and transgenic
t = -11, df = 38, p-value = 0.00000000000008
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-12.54 -8.76
sample estimates:
mean of x mean of y
29.4 40.1
Test t: Varianzas Heterogéneas (Welch)
Si observamos varianzas muy diferentes, usamos la prueba de Welch:
Welch Two Sample t-test
data: wildtype and transgenic
t = -11, df = 37, p-value = 0.0000000000001
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-12.54 -8.76
sample estimates:
mean of x mean of y
29.4 40.1
Test F: Igualdad de Varianzas
Podemos probar formalmente si las varianzas son iguales:
F test to compare two variances
data: wildtype and transgenic
F = 0.7, num df = 19, denom df = 19, p-value = 0.5
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.28 1.79
sample estimates:
ratio of variances
0.707
Cálculo de Potencia
Si el estudio fuera diseñado ahora, ¿qué tamaño muestral necesitaríamos?
Tamaño muestral requerido por grupo: 64
Potencia del estudio observado: 1
Tabla Resumen: Contrastes de Dos Muestras
| Z-test (varianzas conocidas) |
\(Z = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{\sqrt{\sigma_1^2/n_1 + \sigma_2^2/n_2}}\) |
\(N(0,1)\) |
∞ |
Conocidas |
| t-test (varianzas iguales) |
\(T = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{S_p\sqrt{1/n_1 + 1/n_2}}\) |
\(t\) |
\(n_1 + n_2 - 2\) |
Estimadas |
| Welch (varianzas desiguales) |
\(T = \frac{(\bar{X}_1 - \bar{X}_2) - \omega_0}{\sqrt{S_1^2/n_1 + S_2^2/n_2}}\) |
\(t\) (aprox.) |
W-S formula |
Estimadas |
| t pareado |
\(T = \frac{\bar{D} - \omega_0}{S_D/\sqrt{n}}\) |
\(t\) |
\(n - 1\) |
Diferencias |
| F-test |
\(F = \frac{S_1^2}{S_2^2}\) |
\(F\) |
\((n_1-1, n_2-1)\) |
Varianzas |
Resumen
Conceptos Clave
Prueba Z de dos muestras: Para varianzas conocidas, estadístico sigue \(N(0,1)\)
Prueba t de dos muestras (varianzas iguales): Varianza combinada (pooled), grados de libertad \(= n_1 + n_2 - 2\)
Prueba t de Welch: Para varianzas desiguales, usa grados de libertad Welch-Satterthwaite
Prueba t pareada: Reduce a una prueba t de una muestra sobre diferencias
Prueba F: Para comparar varianzas, estadístico \(F = S_1^2 / S_2^2 \sim F_{n_1-1, n_2-1}\)
Potencia Estadística
Potencia (\(1-\beta\)): Probabilidad de rechazar \(H_0\) cuando \(H_1\) es verdadera (detectar un efecto real)
Error Tipo I (\(\alpha\)): Probabilidad de rechazar \(H_0\) cuando es verdadera (típicamente 0.05)
Error Tipo II (\(\beta\)): Probabilidad de no rechazar \(H_0\) cuando \(H_1\) es verdadera (típicamente 0.10-0.20)
Factores que aumentan potencia:
- Mayor tamaño muestral (\(n\))
- Mayor diferencia/efecto a detectar (\(\delta\))
- Menor variabilidad (\(\sigma\))
- Mayor nivel de significancia (\(\alpha\)) — pero aumenta Error Tipo I
Tamaño Muestral
Se calcula especificando: efecto a detectar, potencia deseada, nivel de significancia, variabilidad
Fórmula para t-test bilateral: \(n = \frac{2\sigma^2 (z_{1-\alpha/2} + z_{1-\beta})^2}{\delta^2}\)
Verificación de Supuestos: Normalidad y Homogeneidad
Los contrastes asintóticos basados en el Teorema Central del Límite —como el t-test y el F-test— requieren verificar dos condiciones: (1) normalidad de los datos o residuos, y (2) igualdad de varianzas entre grupos. Con \(n \geq 60\) el TCL garantiza normalidad asintótica de la media, pero para muestras menores conviene comprobarlo formalmente.
Test de Shapiro-Wilk: Normalidad
El test de Shapiro-Wilk (Shapiro & Wilk, 1965) es la prueba de normalidad más potente para muestras pequeñas y moderadas (\(n \leq 5000\)).
Dada una muestra \(x_1, \ldots, x_n\), el estadístico es:
\[W = \frac{\left(\displaystyle\sum_{i=1}^{n} a_i\, x_{(i)}\right)^2}{\displaystyle\sum_{i=1}^{n} (x_i - \bar{x})^2}\]
donde \(x_{(i)}\) son los estadísticos de orden y \(a_i\) son coeficientes tabulados que dependen de la distribución normal estándar.
- \(H_0\): la muestra proviene de una distribución normal
- \(H_1\): la distribución no es normal
- Se rechaza \(H_0\) cuando \(W\) es pequeño (p-valor < \(\alpha\))
- \(W \in (0, 1]\); valores próximos a 1 indican normalidad
Usando el conjunto de datos osteo de BioEstatR, que contiene 94 pacientes diabéticos de la Facultad de Medicina de la UGR, comprobamos la normalidad de la variable edad:
# Test de normalidad de Shapiro-Wilk
-------------------------------------
n = 94, W = 0.907, p < 0.001
Shapiro-Wilk normality test
data: osteo$edad
W = 0.9, p-value = 0.000005
Interpretación: Con \(W = 0.907\) y \(p < 0.001\), rechazamos normalidad (\(\alpha = 0.05\)). Para alternativas cuando no hay normalidad y \(n < 60\), ver ?sec-semana12-bootstrap.
Test de Bartlett: Homogeneidad de Varianzas
El test de Bartlett contrasta si \(k\) grupos independientes tienen la misma varianza poblacional, bajo el supuesto de que los datos son normales.
Sean \(k\) grupos con tamaños \(n_1, \ldots, n_k\) y varianzas muestrales \(s_1^2, \ldots, s_k^2\).
Hipótesis: \(H_0: \sigma_1^2 = \sigma_2^2 = \cdots = \sigma_k^2\) frente a \(H_1\): al menos dos varianzas difieren.
Varianza combinada: \[s_p^2 = \frac{\sum_{j=1}^k (n_j - 1)\,s_j^2}{n - k}, \quad n = \sum_{j=1}^k n_j\]
Estadístico de Bartlett: \[\chi^2_B = \frac{1}{c}\left[(n-k)\ln s_p^2 - \sum_{j=1}^k (n_j - 1)\ln s_j^2\right]\]
donde \(c = 1 + \frac{1}{3(k-1)}\left(\sum_{j=1}^k \frac{1}{n_j - 1} - \frac{1}{n-k}\right)\) es un factor de corrección.
Bajo \(H_0\): \(\chi^2_B \sim \chi^2_{k-1}\) (asintóticamente). Sensible a no normalidad — si los datos no son normales, usar Test de Levene (car::leveneTest()).
Bartlett test of homogeneity of variances
data: imc by grupo_edad
Bartlett's K-squared = 11, df = 2, p-value = 0.004
Interpretación: \(\chi^2_B \approx 10.96\), \(gl = 2\), \(p = 0.004 < 0.05\): se rechaza la igualdad de varianzas. El supuesto de homocedasticidad no se cumple; conviene usar el test de Welch (oneway.test(..., var.equal = FALSE)) o, si los datos no son normales, el test de Levene (car::leveneTest()) y comparaciones no paramétricas como Kruskal-Wallis. Evitar t-test o ANOVA clásico.
| Normalidad |
Shapiro-Wilk |
shapiro.test() |
Siempre si \(n < 60\) |
| Homogeneidad |
Bartlett |
bartlett.test() |
Datos normales |
| Homogeneidad |
Levene |
car::leveneTest() |
Datos no normales |
TCL: Con \(n \geq 60\), el t-test es robusto a la no normalidad (Casella & Berger, 2002). Para \(n < 60\) y datos no normales, ver métodos bootstrap en ?sec-semana12-bootstrap.
Bootstrap y Métodos Robustos como Alternativas
Cuando el test de Shapiro-Wilk rechaza normalidad y el tamaño muestral es insuficiente para garantizar el TCL (\(n < 60\)), los métodos clásicos basados en la distribución \(t\) o \(F\) pueden producir inferencias incorrectas. El bootstrap y los tests de permutación son alternativas válidas que no requieren supuestos distribucionales (Chihara & Hesterberg, 2019).
El bootstrap simula la distribución muestral de un estadístico \(\hat{\theta}\) remuestreando con reemplazo de la muestra original.
Algoritmo del IC bootstrap por percentiles:
Sea \(\mathbf{x} = (x_1, \ldots, x_n)\) la muestra original.
Para \(b = 1, \ldots, B\) (con \(B = 10000\) recomendado):
- Generar muestra bootstrap \(\mathbf{x}^{(b)}\): extraer \(n\) valores con reemplazo de \(\mathbf{x}\)
- Calcular \(\hat{\theta}^{(b)} = T(\mathbf{x}^{(b)})\)
El IC al \((1-\alpha)\)% por percentiles es: \[\left[\hat{\theta}^{*}_{(\alpha/2)}, \; \hat{\theta}^{*}_{(1-\alpha/2)}\right]\] donde los superíndices son cuantiles de la distribución bootstrap \(\{\hat{\theta}^{(b)}\}_{b=1}^{B}\).
El método BCa (Bias-Corrected and Accelerated) ajusta por sesgo y asimetría — es más preciso y se recomienda para muestras pequeñas.
Para contrastar \(H_0: \mu_1 = \mu_2\) (igualdad de medias entre dos grupos), el test de permutación calcula la distribución exacta del estadístico de prueba bajo \(H_0\) permutando aleatoriamente las etiquetas de grupo.
Algoritmo:
- Calcular la diferencia observada: \(D_{\text{obs}} = \bar{x}_1 - \bar{x}_2\)
- Para \(b = 1, \ldots, B\): permutar aleatoriamente las asignaciones de grupo → calcular \(D^{(b)}\)
- p-valor bilateral: \(\hat{p} = \frac{\#\{|D^{(b)}| \geq |D_{\text{obs}}|\}}{B}\)
No requiere normalidad ni homocedasticidad. Válido para cualquier tamano muestral.
El IMC de los pacientes masculinos del dataset osteo no sigue una distribución normal (Shapiro-Wilk: \(W = 0.924\), \(p = 0.006\)). Implementamos el bootstrap manualmente con un bucle for (estilo Chihara & Hesterberg (2019)), siguiendo paso a paso el algoritmo de Efron. Después comparamos con el método BCa (paquete boot) y con el IC clásico \(t\).
Shapiro-Wilk normality test
data: x
W = 0.9, p-value = 0.006
Media muestral observada: 23.5 kg/m²
Réplicas bootstrap (B): 10000
Media bootstrap promedio: 23.5 kg/m²
Error estándar bootstrap: 0.428
IC 95% (percentiles, bucle manual): [ 22.7 , 24.4 ] kg/m²
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 10000 bootstrap replicates
CALL :
boot.ci(boot.out = boot_obj, type = "bca")
Intervals :
Level BCa
95% (22.8, 24.5 )
Calculations and Intervals on Original Scale
[1] 22.6 24.4
attr(,"conf.level")
[1] 0.95
El bootstrap manual con bucle for reproduce paso a paso el algoritmo de Efron (1979): en cada una de las B = 10.000 iteraciones se construye una pseudomuestra extrayendo n = 45 pacientes con reemplazo del IMC observado, se calcula su media, y al final se ordenan las 10.000 medias para extraer los percentiles 2.5% y 97.5%. El IC 95% resultante (≈ [22.7, 24.4] kg/m²) se interpreta clínicamente como el rango plausible del IMC poblacional medio de varones diabéticos —dentro del rango normopeso (18.5–24.9 kg/m²) próximo al umbral del sobrepeso según criterios OMS. Comparado con el IC \(t\) clásico, el bootstrap proporciona inferencia válida sin requerir normalidad, lo cual es relevante en cohortes pequenas con asimetría en la distribución del IMC (común en diabetes tipo 2). El método BCa corrige por sesgo y asimetría y se recomienda como referencia cuando \(n < 30\); con \(n = 45\) los tres intervalos convergen porque el TCL ya comienza a actuar. Esta convergencia se romperá si reducimos n por debajo de 20 o si analizamos variables muy asimétricas (p. ej., triglicéridos o carga viral).
Shapiro-Wilk rechaza normalidad tanto en hombres (\(p = 0.006\)) como en mujeres (\(p = 0.001\)). Usamos un test de permutación en lugar del t-test clásico.
Diferencia observada: -0.78
p-valor permutacion: 0.312
Interpretación: Ambos métodos concuerdan: no hay diferencia significativa en el IMC entre hombres y mujeres (\(p \approx 0.32\)). Cuando los tamaños son moderados (\(n_1 = 45\), \(n_2 = 49\)), el TCL protege al t-test. El test de permutación proporciona validez exacta sin supuestos.
| Normal, \(n\) cualquiera |
t-test, ANOVA clásico |
t.test(), aov() |
| No normal, \(n \geq 60\) |
t-test (TCL garantiza) |
t.test() |
| No normal, \(n < 60\), 1 muestra |
IC Bootstrap BCa |
boot(), boot.ci() |
| No normal, \(n < 60\), 2 grupos |
Permutación o Wilcoxon |
replicate(), wilcox.test() |
| No normal, \(k > 2\) grupos |
Kruskal-Wallis |
kruskal.test() |
| Varianzas desiguales |
Welch t-test |
t.test(var.equal=FALSE) |
Referencia: Chihara & Hesterberg (2019) proporciona una tratamiento riguroso de bootstrap y permutaciones con implementación completa en R, incluyendo la justificación teórica de cada método.
Pruebas No Paramétricas Basadas en Rangos
Las pruebas no paramétricas son alternativas a las pruebas paramétricas (como el t-test o el ANOVA) que no requieren que los datos sigan una distribución normal. Se basan en el rango (posición) de las observaciones en lugar de sus valores originales, lo que las hace robustas frente a valores atípicos (outliers) y distribuciones asimétricas.
Prueba de Wilcoxon-Mann-Whitney (Muestras Independientes)
Es la alternativa no paramétrica al t-test de dos muestras independientes. Contrasta si las distribuciones de dos grupos son idénticas, evaluando si un valor seleccionado al azar de una población tiende a ser mayor que uno de la otra.
Dadas dos muestras independientes de tamaños \(n_1\) y \(n_2\):
- Se combinan ambas muestras y se asignan rangos (de 1 a \(n_1+n_2\)).
- Se calcula la suma de rangos para cada grupo (\(R_1\) y \(R_2\)).
- El estadístico \(U\) es el mínimo de: \[U_1 = n_1n_2 + \frac{n_1(n_1+1)}{2} - R_1, \quad U_2 = n_1n_2 + \frac{n_2(n_2+1)}{2} - R_2\]
Contrastamos si el Índice de Masa Corporal (IMC) difiere entre hombres y mujeres usando la alternativa no paramétrica, dado que el IMC frecuentemente presenta asimetría.
Test de Wilcoxon/Mann-Whithney para dos muestras independientes
----------------------------------------------------------------
# Información muestral ---
Muestra n min Q1 Q2 Q3 max RIQ
1 osteo$imc[osteo$sexo == "Hombre"] 45 18.327 21.436 23.055 24.259 32.323 2.823
2 osteo$imc[osteo$sexo == "Mujer"] 49 18.070 21.155 23.338 26.298 37.333 5.143
# Rangos ---
Muestra n Suma_rangos Rango_medio U
1 osteo$imc[osteo$sexo == "Hombre"] 45 2095 46.556 1145.000
2 osteo$imc[osteo$sexo == "Mujer"] 49 2370 48.367 1060.000
# Test ---
U = 1060.000; Z = 0.322; W = 1060.000; p = 0.750
# Tamaño del efecto ---
Diferencia de localización: -0.193 95%-IC = (-1.595, 0.962)
r = 0.033 (criterio: 0.1 pequeño; 0.3 mediano; >0.5 grande)
Probabilidad de superioridad PS = 0.519
(probabilidad de que un valor al azar de M1 sea < a un valor al azar de M2)
Interpretación: No se observan diferencias significativas en las distribuciones de IMC entre sexos (\(p = 0.751\)). La probabilidad de que un hombre elegido al azar tenga un IMC mayor que una mujer elegida al azar es del 48.1% (calculada como \(1 - PS = 1 - 0.519\), ya que la salida de testwx() reporta \(PS\) como probabilidad de que un valor de \(M_1\) sea menor que uno de \(M_2\)).
Prueba de Wilcoxon de los Rangos con Signo (Muestras Pareadas)
Es la alternativa no paramétrica al t-test pareado. Se utiliza para comparar dos medidas relacionadas (antes-después) sobre los mismos sujetos cuando las diferencias no siguen una distribución normal.
- Calcular las diferencias \(D_i = X_{1i} - X_{2i}\).
- Eliminar las diferencias iguales a cero.
- Asignar rangos a los valores absolutos \(|D_i|\).
- El estadístico \(W\) es la suma de los rangos de las diferencias positivas.
Supongamos que evaluamos el calcio sérico (ca) antes y después de un tratamiento en 10 pacientes (datos simulados para ilustración).
Test de Wilcoxon para dos muestras apareadas
----------------------------------------------
# Información muestral ---
Muestra n min Q1 Q2 Q3 max RIQ
1 ca_pre 10 8.400 8.725 8.950 9.175 9.500 0.450
2 ca_post 10 8.700 8.925 9.050 9.475 9.600 0.550
# Rangos ---
Se obtienen las diferencias como ca_pre - ca_post
Pares de datos efectivos para los rangos: 10 de 10
Muestra n Suma_rangos Rango_medio
1 dif.negativas 10 55 5.500
2 dif.positivas 0 0 NaN
# Test ---
V = 0.000; p = 0.002
z = 2.803; p = 0.005
# Correlación de Spearman ---
rho-Spearman = 0.982; p < 0.001
# Tamaño del efecto ---
Diferencia de localización: (pseudo)mediana = -0.200 95%-IC = (-0.300, -0.100)
r = 0.627; p = 0.002
Interpretacion: Existe un aumento significativo en los niveles de calcio tras el tratamiento (\(p = 0.005\)). El tamaño del efecto es grande (\(r = 0.627\), criterio convencional: \(r > 0.5\) grande).
Prueba de Kruskal-Wallis (K Muestras Independientes)
Es la alternativa no paramétrica al ANOVA de un factor. Se utiliza para comparar las medianas de tres o más grupos independientes.
Para \(k\) grupos con tamaños \(n_j\) y suma de rangos \(R_j\):
\[H = \frac{12}{n(n+1)} \sum_{j=1}^k \frac{R_j^2}{n_j} - 3(n+1)\]
donde \(n = \sum n_j\). Bajo \(H_0\), \(H \sim \chi^2_{k-1}\) asintóticamente.
Kruskal-Wallis rank sum test
data: imc by grupo_edad
Kruskal-Wallis chi-squared = 17, df = 2, p-value = 0.0002
Interpretación: Como \(p \approx 0.0002 < 0.05\), rechazamos la hipótesis de igualdad. Al menos un grupo de edad tiene una distribución de IMC significativamente distinta.
Ejercicios
Ejercicio 8.1: Se comparan dos métodos de enseñanza en estadística. El Método A (n₁ = 30) tiene media 75 y desviación estándar 8. El Método B (n₂ = 35) tiene media 78 y desviación estándar 7. ¿Hay diferencia significativa entre los métodos a nivel α = 0.05? (Suponga varianzas iguales)
Ejercicio 8.2: Un investigador mide presión arterial en 10 pacientes antes y después de tomar un medicamento. Las diferencias promedio son -5 mmHg con desviación estándar 8 mmHg. ¿Es el medicamento efectivo en reducir presión (prueba unilateral, α = 0.05)?
Ejercicio 8.3: Se comparan dos proveedores de materia prima. Proveedor 1: S₁² = 15, n = 20. Proveedor 2: S₂² = 8, n₂ = 18. ¿Hay diferencia significativa en variabilidad (α = 0.05, bilateral)?
Ejercicio 8.4: Se diseña un estudio para detectar una diferencia de 12 puntos en una escala (σ = 10) con potencia 0.90 y α = 0.05. ¿Cuántos sujetos se necesitan por grupo?
Ejercicio 8.5: Un investigador realiza 15 pruebas independientes con α = 0.05 sin corrección. ¿Cuál es la probabilidad aproximada de cometer al menos un Error Tipo I?
Ejercicio 8.6: Interprete este resultado de R: t.test(x, y, var.equal=FALSE) da t = 2.34, df = 45.2, p-value = 0.024. ¿Qué conclusión saca?
Ejercicio 8.7: Un estudio observa media₁ = 100, media₂ = 105, pero el intervalo de confianza al 95% para la diferencia incluye cero. ¿Qué significa esto respecto a la significancia estadística y práctica?
Ejercicio 8.8: Si el test de Shapiro-Wilk rechaza la normalidad en una muestra pequeña (\(n=15\)), ¿qué prueba utilizaría para comparar dos grupos independientes?
Ejercicio 8.9: ¿Cuál es la principal ventaja de la prueba de Kruskal-Wallis sobre el ANOVA de un factor?
Ejercicio 8.10: En una muestra de 35 valores de presión arterial sistólica, el test de Shapiro-Wilk produce \(W = 0.94\) con \(p = 0.089\). ¿Es válido aplicar un test t de una muestra con \(\alpha = 0.05\)? ¿Cambiaría su decisión si \(n = 75\)?
Respuestas a los Ejercicios
Ejercicio 8.1: t = (75-78)/√((29×64 + 34×49)/(63) × (1/30 + 1/35)) ≈ -1.81; df ≈ 63; p > 0.05. No hay diferencia significativa.
Ejercicio 8.2: t = -5/(8/√10) ≈ -1.98; df = 9; p ≈ 0.038 < 0.05. El medicamento es efectivo en reducir presión.
Ejercicio 8.3: F = 15/8 = 1.875; df₁ = 19, df₂ = 17. F crítico ≈ 2.74. No rechaza H₀; no hay diferencia significativa en variabilidad.
Ejercicio 8.4: Usando fórmula de potencia: n ≈ 2×(10)²×(1.96 + 1.28)²/(12)² ≈ 29-30 sujetos por grupo.
Ejercicio 8.5: P(al menos 1 error) = 1 - (1-0.05)¹⁵ ≈ 1 - 0.463 = 0.537 (53.7%). El problema de multiplicidad es importante.
Ejercicio 8.6: t = 2.34, df = 45.2, p = 0.024 < 0.05. Se rechaza H₀. Hay diferencia significativa entre x e y (usando Welch’s t-test por varianzas desiguales).
Ejercicio 8.7: Si el IC 95% incluye cero, la diferencia no es estadísticamente significativa (p > 0.05), aunque hay diferencia práctica de 5 unidades. Sin significancia estadística, no podemos afirmar que la diferencia poblacional es real.
Ejercicio 8.8: Utilizaría la prueba de Wilcoxon-Mann-Whitney (o un test de permutación).
Ejercicio 8.9: No requiere el supuesto de normalidad en los datos, siendo más robusta cuando hay outliers o distribuciones muy asimétricas.
Ejercicio 8.10: Con \(p = 0.089 > 0.05\), no rechazamos \(H_0\) de normalidad → el test t es válido. Con \(n = 75\), el TCL garantiza normalidad asintótica de la media, por lo que el test t es válido independientemente del resultado de Shapiro-Wilk.
Recursos Adicionales
- Software R: Funciones
t.test(), var.test(), power.t.test(), wilcox.test(), kruskal.test() en stats
- OpenIntro Statistics: Capítulos sobre comparación de dos medias y potencia
- Referencias clásicas: Rosner (2011) Fundamentals of Biostatistics; Kahn & Sempos (2002) Statistical Methods in Epidemiology
Casella, G., & Berger, R. L. (2002). Statistical Inference (2nd ed.). Duxbury Press.
Chihara, L. M., & Hesterberg, T. C. (2019). Mathematical Statistics with Resampling and R (2nd ed.). Wiley.
Shapiro, S. S., & Wilk, M. B. (1965). An Analysis of Variance Test for Normality (Complete Samples). Biometrika, 52(3–4), 591-611.