Introducción
El análisis exploratorio de datos (AED) es el primer paso en cualquier análisis estadístico. A través de visualizaciones, tablas y estadísticos descriptivos, aprendemos a entender las características principales de un conjunto de datos antes de realizar inferencia estadística más compleja.
Conceptos Fundamentales
Unidades Estadísticas, Variables y Valores
En estadística trabajamos con conceptos fundamentales que debemos dominar desde el principio.
Unidad estadística (o individuo): cada elemento sobre el que se realiza la observación. Puede ser una persona, animal, planta, empresa, etc.
Variable: una característica de una unidad estadística que puede variar de una unidad a otra. Se denota con letras mayúsculas (\(X\), \(Y\), etc.)
Valor: el resultado específico de observar una variable en una unidad estadística. Se denota con letras minúsculas (\(x_i\), \(y_i\), etc.)
Población: el conjunto completo de todas las unidades estadísticas de interés en un estudio.
Muestra: un subconjunto de la población observado en la práctica. La muestra se utiliza para extraer conclusiones sobre la población.
Supongamos que deseamos estudiar la presión arterial sistólica (PAS) en pacientes diabéticos de Granada.
- Unidad estadística: cada paciente diabético individual
- Variable: presión arterial sistólica (\(X\))
- Valores: mediciones específicas en mmHg (ej. \(x_1 = 125\), \(x_2 = 130\), \(x_3 = 145\), …)
- Población: todos los pacientes diabéticos de Granada
- Muestra: los 200 pacientes diabéticos seleccionados para el estudio
Observaciones Atípicas (Outliers)
Un outlier (observación atípica) es un valor que:
- Parece desviarse marcadamente de los otros miembros de la muestra
- Aparece o está ausente de forma inesperada
- Puede reflejar una anomalía en la característica medida o un error en la medición/registro
Ejemplo: En el conjunto de presiones arteriales sistólicas \(\{125, 128, 130, 131, 198\}\), el valor \(198\) podría considerarse un outlier, ya que es sustancialmente mayor que los otros valores.
Escalas de Medición
El tipo de escala utilizada para medir una variable determina qué técnicas analíticas son apropiadas y qué conclusiones se pueden extraer.
Las variables se clasifican en cuatro tipos según la escala en que se miden:
- Variables nominales (categóricas sin orden)
- Variables ordinales (categóricas con orden)
- Variables discretas (numéricas, valores aislados)
- Variables continuas (numéricas, infinitos valores posibles)
Variables Categóricas
Una variable categórica es aquella que puede tomar uno de un conjunto limitado de valores posibles, asignando cada unidad a una categoría particular basada en una propiedad cualitativa.
Ejemplos:
- Grupo sanguíneo: A, B, AB, O
- Estado civil: soltero, casado, divorciado, viudo
- Género: masculino, femenino
- Región: Andalucía, Cataluña, Madrid, etc.
Los valores de una variable categórica se llaman niveles.
Las variables categóricas pueden ser:
- Binarias (dicotómicas): solo dos niveles (ej. éxito/fracaso, enfermo/sano)
- Politómicas: más de dos niveles (ej. grupo sanguíneo)
Variables Ordinales
Una variable ordinal es una variable categórica en la que los niveles tienen un orden natural, pero las diferencias entre ellos no son cuantificables.
Relaciones válidas: “mayor que” y “menor que” (o “mejor que” y “peor que”).
Ejemplos:
- Estadio de un tumor: I, II, III, IV
- Grado de dependencia: leve, moderada, severa, total
- Escala de dolor: nada, poco, moderado, intenso, insoportable
Variables Numéricas
Una variable discreta es una variable numérica que solo puede tomar un número finito o contablemente infinito de valores. Cada valor tiene vecinos claramente identificables.
Ejemplos:
- Número de nacimientos en un mes
- Número de episodios de hipoglucemia
- Número de dientes extraídos
- Cantidad de admisiones previas en el hospital
Una variable continua es una variable numérica que puede tomar infinitos valores no contables. Entre dos valores cualesquiera siempre existen otros valores posibles.
Ejemplos:
- Presión arterial sistólica (en mmHg)
- Peso corporal (en kg)
- Altura (en cm)
- Temperatura (en °C)
En la práctica: variables con muchas unidades contables (como el recuento de glóbulos rojos o blancos) se tratan como continuas y a veces se llaman “cuasi-continuas”.
Agrupación de Datos en Clases (Binning)
Cuando disponemos de muchas observaciones de una variable continua, frecuentemente es útil agruparlas en intervalos de clase para mejorar la claridad.
El binning es la partición de los valores de una variable continua en varias clases (típicamente intervalos). Esto mejora la claridad cuando se tiene gran cantidad de datos.
Para cada intervalo o clase \(j\) definimos:
- Límite inferior de la clase: \(x_j^l\)
- Límite superior de la clase: \(x_j^u\)
- Amplitud de la clase: \(\Delta x_j = x_j^u - x_j^l\)
Propiedades importantes:
- Los intervalos son no superpuestos (disjuntos) y adyacentes
- \(x_j^u = x_{j+1}^l\) (el límite superior de una clase es el límite inferior de la siguiente)
- Convencionalmente: \(x_j^l < X \leq x_j^u\) (incluimos el límite superior, excluimos el inferior)
En un estudio sobre salud cardiovascular tenemos:
- Unidad estadística: paciente
- Variable: nivel de colesterol total (en mg/dL)
| 150 – 200 (Deseable) |
\(x_1^l = 150\), \(x_1^u = 200\) |
\(\Delta x_1 = 50\) |
| 200 – 240 (Límite alto) |
\(x_2^l = 200\), \(x_2^u = 240\) |
\(\Delta x_2 = 40\) |
| 240 – 300 (Alto) |
\(x_3^l = 240\), \(x_3^u = 300\) |
\(\Delta x_3 = 60\) |
Tablas de Frecuencias y Distribución Empírica
Una forma eficaz de resumir un conjunto de datos es construir una tabla de frecuencias.
Frecuencias Absolutas y Relativas
La frecuencia absoluta de un valor \(x_j\) es el número de unidades estadísticas con ese valor característico:
\[h(x_j) = h_j\]
Propiedades: \[0 \leq h(x_j) \leq n, \quad \sum_{j=1}^{k} h(x_j) = n\]
donde \(n\) es el número total de observaciones y \(k\) es el número de valores distintos.
La frecuencia relativa de un valor \(x_j\) es la proporción de unidades estadísticas con ese valor:
\[f(x_j) = \frac{h(x_j)}{n}\]
Propiedades: \[0 \leq f(x_j) \leq 1, \quad \sum_{j=1}^{k} f(x_j) = 1\]
La frecuencia relativa es útil para comparar distribuciones de diferentes tamaños.
Tabla de Frecuencias
Una distribución de frecuencias empírica es una tabla que lista los valores (o intervalos de valores) de una variable junto con sus frecuencias (absolutas o relativas).
Estructura de una tabla de frecuencias:
| \(x_1\) |
\(h_1\) |
\(f_1\) |
| \(x_2\) |
\(h_2\) |
\(f_2\) |
| … |
… |
… |
| \(x_k\) |
\(h_k\) |
\(f_k\) |
| Suma |
n |
1 |
Frecuencias Acumuladas
La frecuencia acumulada es la suma de las frecuencias de todos los valores hasta un punto determinado.
Frecuencia acumulada absoluta: \[H(x_j) = \sum_{i=1}^{j} h(x_i), \quad j = 1, \ldots, k\]
Frecuencia acumulada relativa: \[F(x_j) = \frac{H(x_j)}{n} = \sum_{i=1}^{j} f(x_i), \quad j = 1, \ldots, k\]
Propiedades:
- \(H(x_1) = h(x_1)\) y \(F(x_1) = f(x_1)\)
- \(H(x_k) = n\) y \(F(x_k) = 1\)
- Las frecuencias acumuladas son secuencias no decrecientes
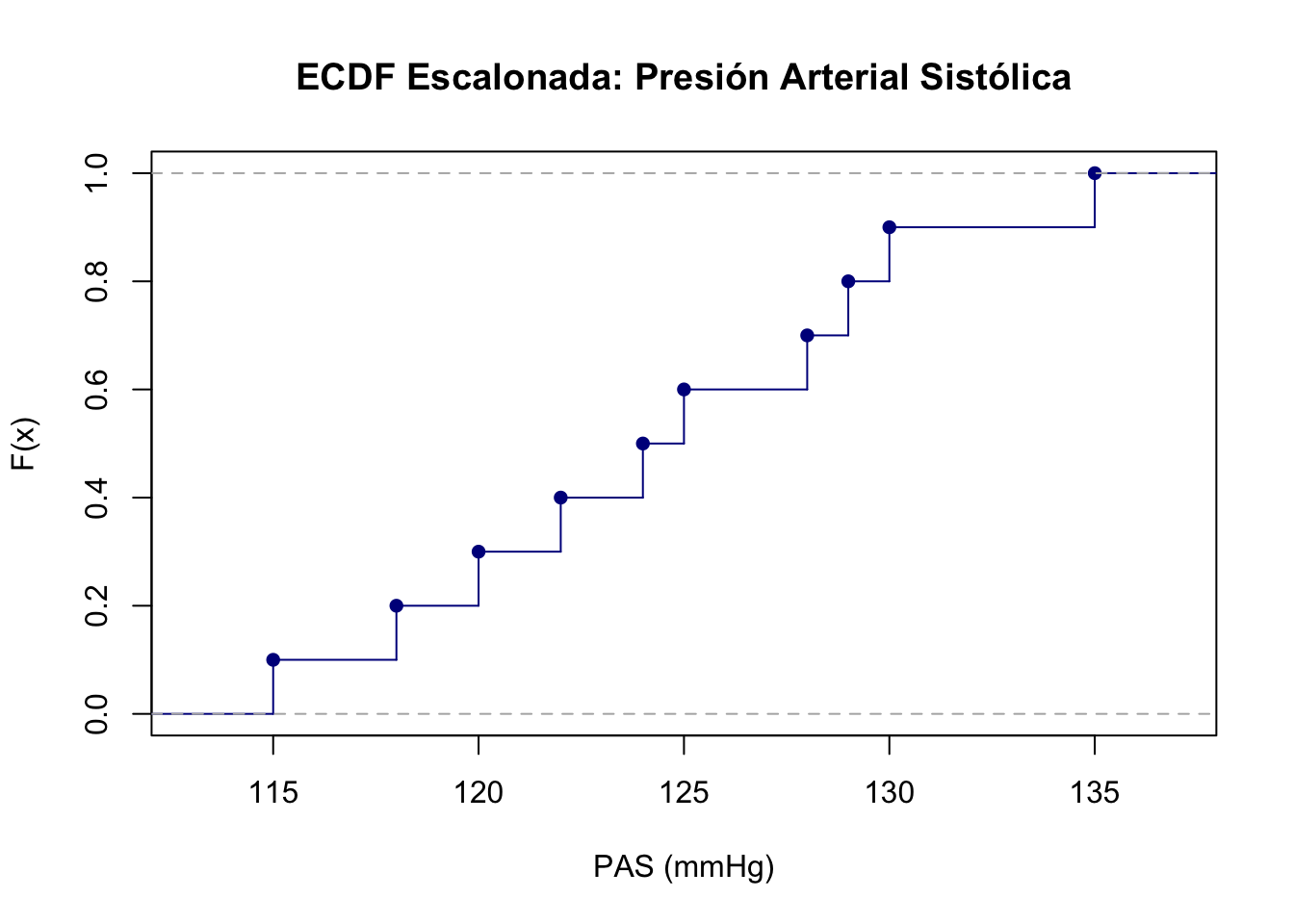
Consideremos los datos de 10 pacientes diabéticos. Sus presiones arteriales sistólicas (en mmHg) son: 120, 125, 118, 130, 122, 128, 115, 135, 124, 129
| 115 |
1 |
0.10 |
1 |
0.10 |
| 118 |
1 |
0.10 |
2 |
0.20 |
| 120 |
1 |
0.10 |
3 |
0.30 |
| 122 |
1 |
0.10 |
4 |
0.40 |
| 124 |
1 |
0.10 |
5 |
0.50 |
| 125 |
1 |
0.10 |
6 |
0.60 |
| 128 |
1 |
0.10 |
7 |
0.70 |
| 129 |
1 |
0.10 |
8 |
0.80 |
| 130 |
1 |
0.10 |
9 |
0.90 |
| 135 |
1 |
0.10 |
10 |
1.00 |
Podemos observar que todas las presiones son diferentes en este ejemplo, por lo que cada una aparece una sola vez.
PAS h f H F
115 1 0.1 1 0.1
118 1 0.1 2 0.2
120 1 0.1 3 0.3
122 1 0.1 4 0.4
124 1 0.1 5 0.5
125 1 0.1 6 0.6
128 1 0.1 7 0.7
129 1 0.1 8 0.8
130 1 0.1 9 0.9
135 1 0.1 10 1.0
La función freq() genera automáticamente la tabla de frecuencias con proporciones y acumuladas (documentación completa en Sección B.2):
Distribución de frecuencias
--------------------------------
Variable: osteo$edad
n = 94
x Freq Prop Prop.Acum
1 (18,23] 27 0.287 0.287
2 (23,28] 22 0.234 0.521
3 (28,33] 14 0.149 0.670
4 (33,38] 15 0.160 0.830
5 (38,43] 4 0.043 0.873
6 (43,48] 5 0.053 0.926
7 (48,53] 3 0.032 0.958
8 (53,58] 3 0.032 0.990
El 52.1% de los pacientes tiene 28 años o menos (la columna Prop.Acum del intervalo (23,28] muestra 0.521). Con grf = TRUE (por defecto) también se genera el histograma. Con cuts = 5 agrupa en 5 clases de igual amplitud.
Función de Distribución Empírica (ECDF)
La Función de Distribución Empírica (ECDF) asigna a cada valor \(x\) la proporción de observaciones en la muestra que son menores o iguales a \(x\).
Para datos no agrupados, la ECDF es una función escalonada que salta en cada valor observado:
\[F(x) = \begin{cases}
0 & \text{si } x < x_{(1)} \\
\frac{i}{n} & \text{si } x_{(i)} \leq x < x_{(i+1)} \\
1 & \text{si } x \geq x_{(n)}
\end{cases}\]
donde \(x_{(1)} \leq x_{(2)} \leq \cdots \leq x_{(n)}\) son los valores ordenados de la muestra.
Usando los datos de PAS del Ejemplo 1.3, observamos cómo la función acumula probabilidad en saltos de \(1/n\) en cada valor observado:
De la ECDF podemos recuperar las frecuencias relativas mediante:
\[f(x_j) = F(x_j) - F(x_{j-1}) \quad \text{para } j = 1, \ldots, k\]
con la convención \(F(x_0) = 0\).
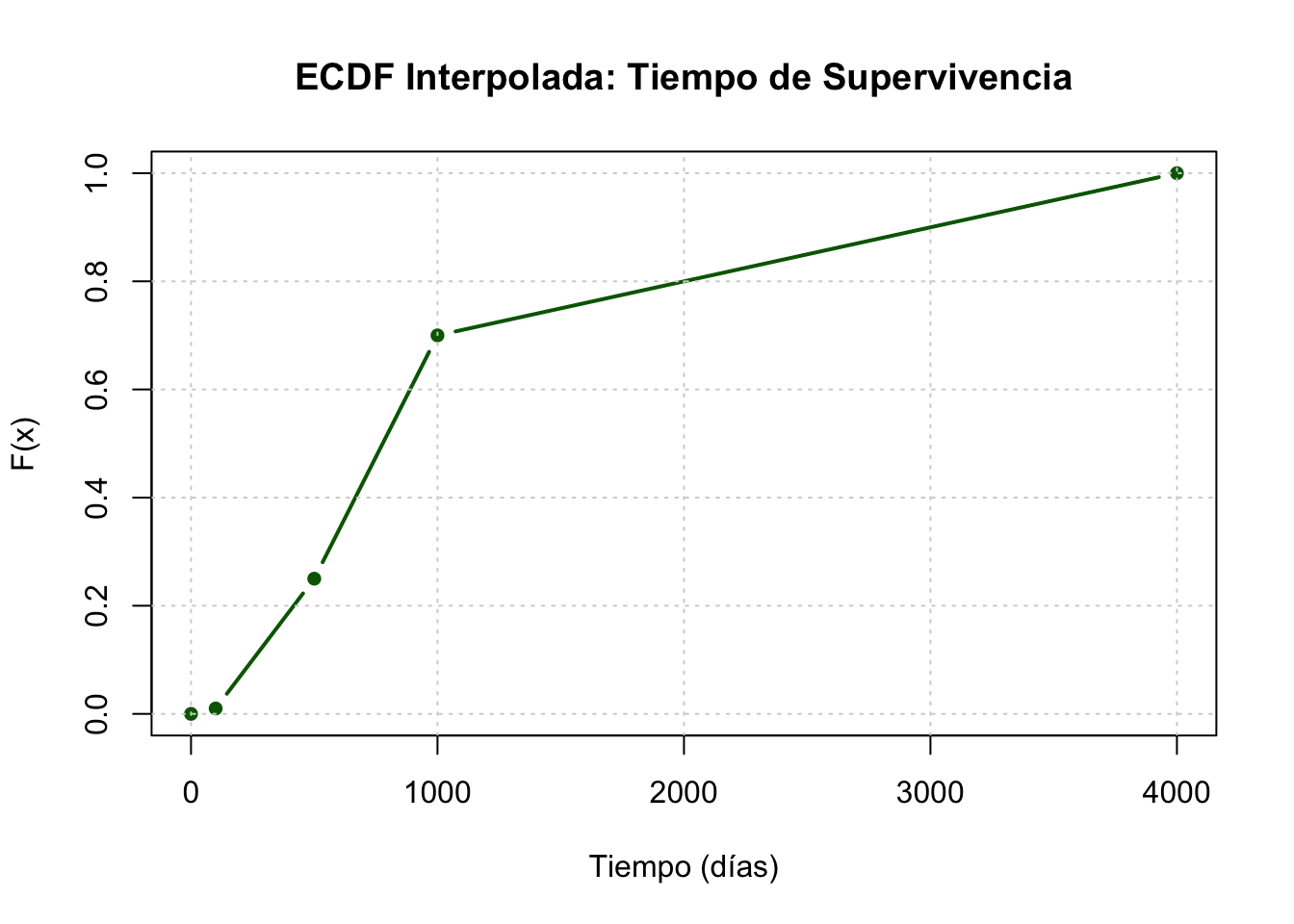
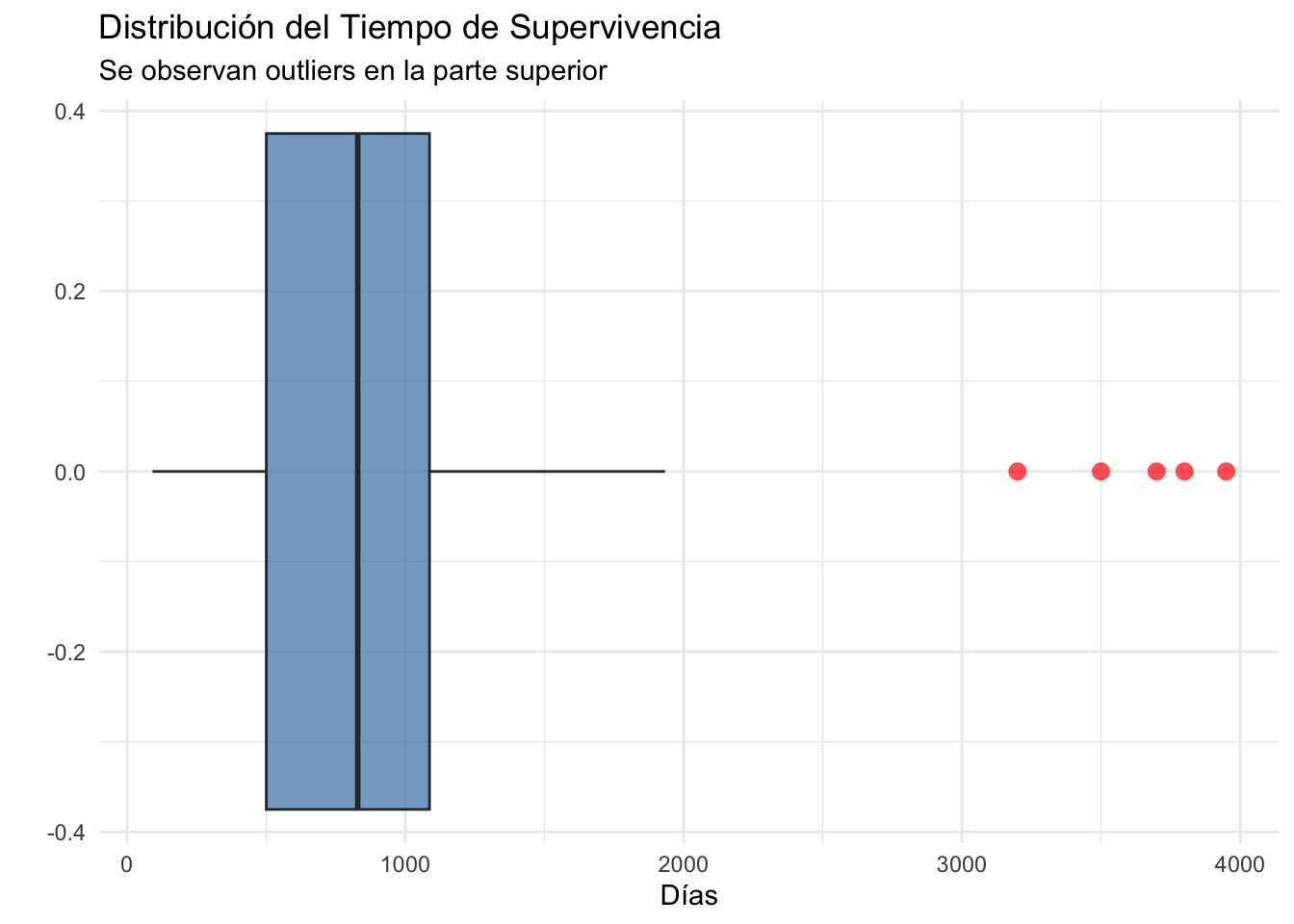
Se estudió el tiempo de supervivencia (en días) tras el diagnóstico de una patología agresiva en una cohorte de 100 pacientes. Los datos se agrupan en clases:
| 0 – 100 |
1 |
0.01 |
1 |
0.01 |
| 100 – 500 |
24 |
0.24 |
25 |
0.25 |
| 500 – 1000 |
45 |
0.45 |
70 |
0.70 |
| 1000 – 4000 |
30 |
0.30 |
100 |
1.00 |
| Total |
100 |
1.00 |
|
|
Interpolación Lineal para Datos Agrupados
Para datos agrupados, no conocemos los valores exactos dentro de cada clase. Por ello, aproximamos la ECDF mediante una interpolación lineal entre los límites de las clases. Esto genera una línea quebrada llamada polígono de frecuencias acumuladas (u ojiva).
La fórmula general de interpolación para un valor \(x\) dentro de la clase \(j = [x_j^l, x_j^u]\) es:
\[F(x) = F(x_j^l) + \frac{x - x_j^l}{x_j^u - x_j^l} \cdot f(x_j)\]
Donde:
- \(x_j^l\) y \(x_j^u\) son los límites inferior y superior de la clase.
- \(F(x_j^l)\) es la frecuencia relativa acumulada hasta la clase anterior.
- \(f(x_j)\) es la frecuencia relativa de la clase actual.
Nota: Esta fórmula es la base para estimar cuantiles en datos agrupados. Si despejamos \(x\) para un valor de \(F(x) = p\), obtenemos el valor del cuantil correspondiente.
Aplicando esto a nuestros datos:
\[F(x) = \begin{cases}
0 & \text{si } x \leq 0 \\
\frac{x - 0}{100} \cdot 0.01 & \text{si } 0 < x \leq 100 \\
0.01 + \frac{x - 100}{400} \cdot 0.24 & \text{si } 100 < x \leq 500 \\
0.25 + \frac{x - 500}{500} \cdot 0.45 & \text{si } 500 < x \leq 1000 \\
0.70 + \frac{x - 1000}{3000} \cdot 0.30 & \text{si } 1000 < x \leq 4000 \\
1 & \text{si } x > 4000
\end{cases}\]
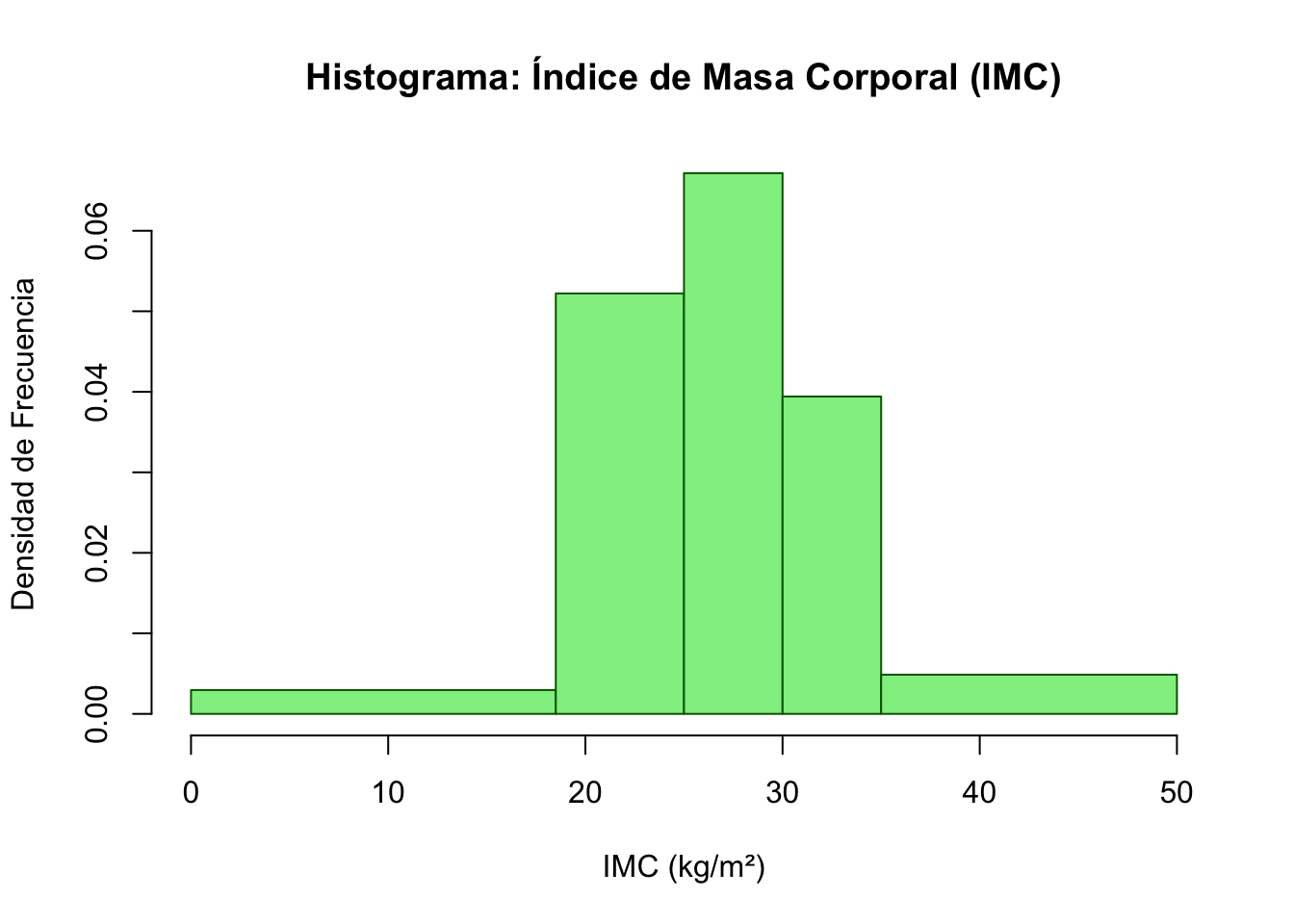
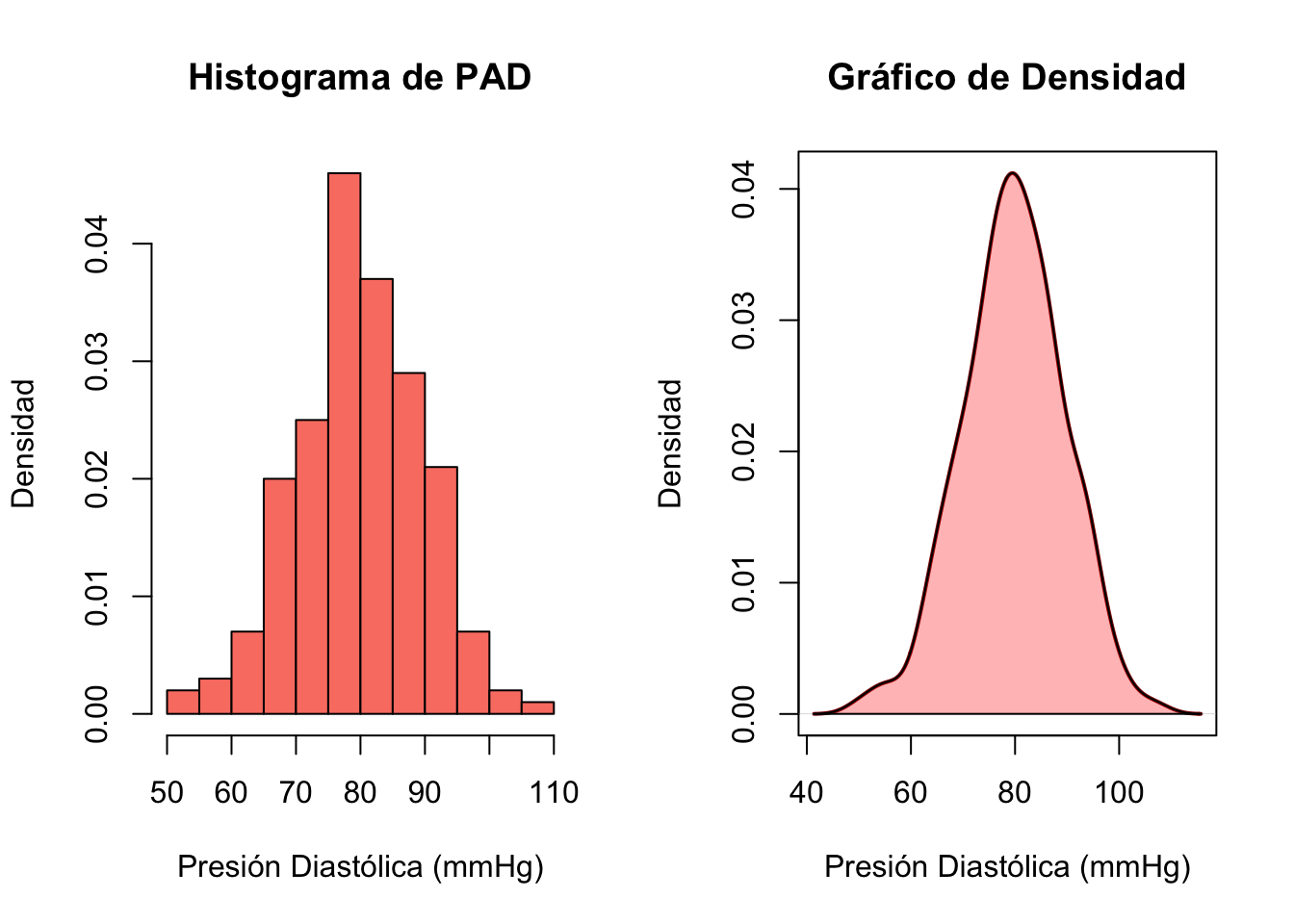
Histogramas y Gráficos de Densidad
Para variables continuas agrupadas en clases, el histograma es la forma estándar de visualización.
Construcción de Histogramas
Un histograma es una representación gráfica de una distribución de frecuencias para datos agrupados. Se construye de la siguiente manera:
- Eje X: límites de las clases \(x_j^l, x_j^u\)
- Eje Y: densidad de frecuencia (frecuencia dividida por la amplitud de la clase)
Densidad de frecuencia absoluta: \[\hat{h}(x_j) = \frac{h(x_j)}{\Delta x_j} = \frac{h(x_j)}{x_j^u - x_j^l}\]
Densidad de frecuencia relativa: \[\hat{f}(x_j) = \frac{f(x_j)}{\Delta x_j} = \frac{f(x_j)}{x_j^u - x_j^l}\]
Propiedad fundamental: El área de cada rectángulo representa la frecuencia (relativa o absoluta), y el área total del histograma es igual a \(n\) (si usamos densidades absolutas) o \(1\) (si usamos densidades relativas).
\[\sum_{j=1}^{k} \hat{f}(x_j) \cdot \Delta x_j = \sum_{j=1}^{k} f(x_j) = 1\]
Se recopilaron los IMC de 274 pacientes. Los datos se clasifican en intervalos según los criterios de la OMS:
| 0 – 18.5 (Bajo peso) |
15 |
0.055 |
18.5 |
0.0030 |
| 18.5 – 25 (Normal) |
93 |
0.339 |
6.5 |
0.0522 |
| 25 – 30 (Sobrepeso) |
92 |
0.336 |
5 |
0.0672 |
| 30 – 35 (Obesidad I) |
54 |
0.197 |
5 |
0.0394 |
| 35 – 50 (Obesidad II/III) |
20 |
0.073 |
15 |
0.0049 |
| Total |
274 |
1.000 |
|
|
Interpretación: La densidad más alta está en la clase de “Sobrepeso”, indicando que ese intervalo tiene la mayor concentración de pacientes en esta muestra.
:::
Histograma vs Gráfico de Densidad
Clasificación de Medidas Estadísticas
Para describir una distribución, utilizamos diferentes medidas que resumen la información.
- Medidas de Tendencia Central: Buscan identificar el “valor representativo” o centro de la distribución.
- Media (\(\bar{x}\)): Promedio aritmético.
- Mediana (\(\tilde{x}\)): Valor central (posición central).
- Moda (\(Mo\)): Valor más frecuente.
- Medidas de Posición (No central): Indican la posición de un valor respecto al conjunto de datos, permitiendo dividir la distribución en partes iguales.
- Cuartiles (\(Q_1, Q_2, Q_3\)): Dividen los datos en 4 partes iguales.
- Percentiles (\(P_k\)): Dividen los datos en 100 partes iguales.
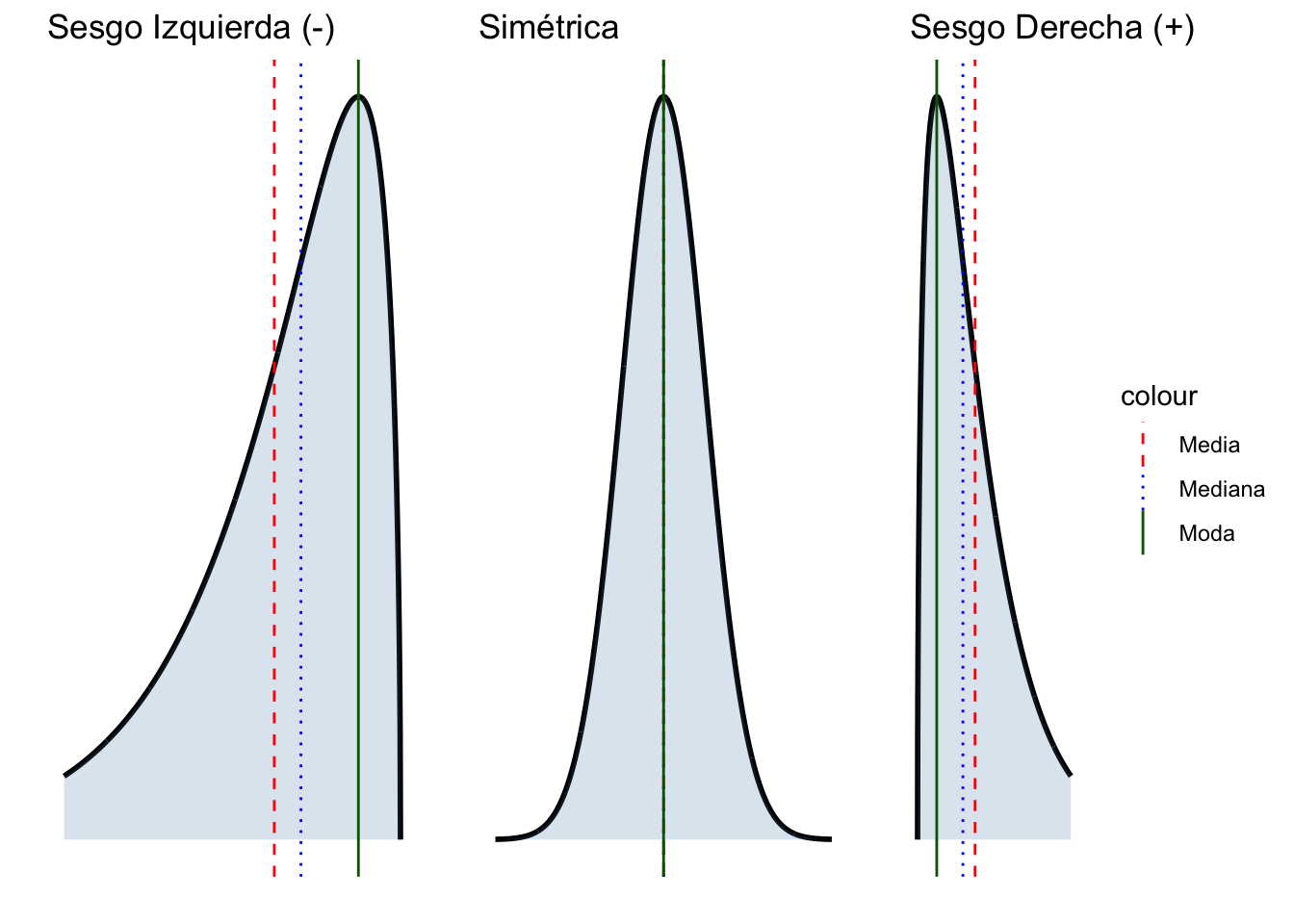
- Sesgo (Skewness): Medida de asimetría.
- Simétrica: Media \(\approx\) Mediana.
- Sesgo Derecha (Positivo): Media > Mediana.
- Sesgo Izquierda (Negativo): Media < Mediana.
- Curtosis (Kurtosis): Medida del grado de apuntamiento o concentración en las colas.
Medidas de Posición Central
Las medidas de posición central nos indican dónde se concentran los datos. Son fundamentales para resumir la tendencia central de una distribución.
Moda
La moda \(x_D\) es el valor más frecuente en un conjunto de observaciones:
\[x_D = \{x_j \mid h(x_j) = \max_k h(x_k) \text{ o } f(x_j) = \max_k f(x_k)\}\]
Es útil para variables nominales, ordinales, discretas o clasificadas, pero no es apropiada para variables continuas.
Para datos agrupados, hablamos de la clase modal (la clase con la frecuencia más alta) y estimamos la moda como la marca de clase.
Usando la tabla de supervivencia del Ejemplo 1.6:
| 0 – 100 |
1 |
| 100 – 500 |
24 |
| 500 – 1000 |
45 (máximo) |
| 1000 – 4000 |
30 |
- Clase modal: 500 – 1000 días
- Moda estimada: \(x_D = 750\) días (marca de clase)
Comparación de Medidas de Posición
La media es muy sensible a valores extremos (outliers):
- Fácil de calcular algebraicamente
- Propiedad de suma útil para combinación de datos
- Se ve afectada por datos atípicos
La mediana es robusta:
- Insensible a outliers
- Más representativa en distribuciones asimétricas
- Requiere ordenar los datos
La moda es útil para datos categóricos pero limitado para continuos.
Recomendación: En presencia de outliers, la mediana es preferible a la media como medida de tendencia central.
Resumen de Conceptos Clave
Tabla Resumen: Escalas de Medición y Estadísticos Apropiados
| Nominal |
Género, grupo sanguíneo |
Moda, frecuencias |
| Ordinal |
Satisfacción, grado |
Mediana, moda, cuantiles |
| Discreta |
Número de eventos |
Media, mediana, varianza |
| Continua |
Peso, presión arterial |
Media, mediana, varianza, cuantiles |
Tabla Resumen: Fórmulas Importantes
| Media (\(\bar{x}\)) |
\(\frac{1}{n}\sum_{i=1}^{n} x_i\) |
\(\sum_{j=1}^{k} x_j f_j\) (\(x_j\): marca clase) |
| Mediana/Cuantil (\(x_p\)) |
Valor en pos. ordenado |
\(x_j^l + \frac{p - F(x_j^l)}{f(x_j)} \cdot \Delta x_j\) |
| Moda (\(Mo\)) |
Valor con máx. \(h_j\) |
Marca de la clase modal |
| ECDF (\(F(x)\)) |
Función escalonada |
Interpolación lineal (ojiva) |
| Sesgo (\(g_1\)) |
\(\frac{\frac{1}{n} \sum (x_i - \bar{x})^3}{s^3}\) |
(Aprox. marcas de clase) |
| Curtosis (\(g_2\)) |
\(\frac{\frac{1}{n} \sum (x_i - \bar{x})^4}{s^4}\) |
(Aprox. marcas de clase) |
Ejercicios
Define con tus propias palabras (desde una perspectiva clínica): a) La diferencia entre una variable y un valor (ej. Glucemia) b) Por qué necesitamos distinguir entre población y muestra en un ensayo clínico c) Qué es un outlier y cómo podría afectar a la media de una serie de mediciones de tensión arterial
Para cada una de las siguientes variables clínicas, identifica la escala de medición (nominal, ordinal, discreta, continua) y justifica tu respuesta:
- Número de episodios asmáticos al año
- Gravedad de una quemadura (Primer, Segundo, Tercer grado)
- Concentración de hemoglobina en sangre (g/dL)
- Factor Rh (Positivo, Negativo)
- Escala de coma de Glasgow (puntuación de 3 a 15)
Se registraron los tiempos de espera (en minutos) en urgencias de 8 pacientes: 12, 8, 15, 10, 7, 14, 9, 11
- Calcula la media aritmética
- Ordena los datos y encuentra la mediana
- ¿Cuál es más representativa en este caso? ¿Por qué?
Los siguientes datos representan el número de admisiones hospitalarias previas para 20 pacientes crónicos: 3, 2, 5, 2, 4, 3, 6, 2, 3, 4, 5, 2, 3, 4, 2, 5, 3, 6, 4, 2
- Construye una tabla de frecuencias (absoluta, relativa, acumulada)
- ¿Cuál es la moda (número más frecuente de admisiones)?
- ¿Qué proporción de pacientes tuvieron 3 o menos admisiones?
Se agrupan los niveles de glucosa en ayunas (mg/dL) de 100 pacientes en riesgo de diabetes:
| 70 – 90 |
15 |
| 90 – 100 |
32 |
| 100 – 110 |
35 |
| 110 – 126 |
15 |
| 126 – 150 |
3 |
- Calcula la media aproximada de la glucemia
- Identifica la clase modal
- Estima el percentil 50 (mediana) usando interpolación
[1] "Media aproximada: 100.99 mg/dL"
Clase Frecuencia F_acum
1 70-90 15 0.15
2 90-100 32 0.47
3 100-110 35 0.82
4 110-126 15 0.97
5 126-150 3 1.00
Considera el histograma de IMC del Ejemplo 1.7:
- ¿Qué clase tiene la mayor densidad de pacientes?
- ¿Qué porcentaje de pacientes tienen un IMC inferior a 25 (Normal o bajo peso)?
- ¿En qué rango se encuentra el 25% de pacientes con menor IMC?
Respuestas a los Ejercicios
Ejercicio 1.1: Conceptos a) Variable: Característica (Glucemia). Valor: Resultado medido (105 mg/dL). b) Población: Todos los pacientes con la patología. Muestra: Los que participan en el estudio. c) Un outlier (ej. una medición de 220/120 por error de manguito) elevaría artificialmente la media, haciendo que la tensión promedio parezca más alta de lo que realmente es.
Ejercicio 1.2: Escalas a) Discreta (conteo de eventos). b) Ordinal (hay un orden de gravedad). c) Continua (puede tomar cualquier valor decimal). d) Nominal (categorías sin orden). e) Ordinal (puntuación con orden intrínseco).
Ejercicio 1.3: Tiempos de espera a) Media = 86 / 8 = 10.75 min. b) Ordenados: 7, 8, 9, 10, 11, 12, 14, 15. Mediana = (10+11)/2 = 10.5 min. c) Ambas son similares porque no hay outliers extremos.
Ejercicio 1.4: Admisiones a)
| 2 |
6 |
0.30 |
6 |
0.30 |
| 3 |
5 |
0.25 |
11 |
0.55 |
| 4 |
4 |
0.20 |
15 |
0.75 |
| 5 |
3 |
0.15 |
18 |
0.90 |
| 6 |
2 |
0.10 |
20 |
1.00 |
| Total |
20 |
1.00 |
|
|
- Moda = 2 admisiones (\(h_j=6\)). c) Proporción = \(F_3 = 0.55\) (55%).
Ejercicio 1.5: Glucemia a) Media ≈ 100.99 mg/dL (cálculo: \((80{\cdot}15 + 95{\cdot}32 + 105{\cdot}35 + 118{\cdot}15 + 138{\cdot}3)/100\)). b) Clase modal: 100-110 mg/dL (\(h_j = 35\)). c) P₅₀ ≈ 100 + (0.50 - 0.47)/0.35 · 10 ≈ 100.86 mg/dL (la mediana cae en la clase 100-110, donde \(F\) pasa de 0.47 a 0.82).
Ejercicio 1.6: IMC (Ejemplo 1.7) a) Sobrepeso (25-30) con densidad 0.0672. b) \(F(25) = 0.055 + 0.339 = 0.394\) (39.4%). c) En el rango de 0 a 25 (específicamente, el P₂₅ está en la clase “Normal”).
Fin de Semana 1
Para referencias avanzadas sobre análisis exploratorio de datos y estimación robusta, consulta: Robust Estimation of Location