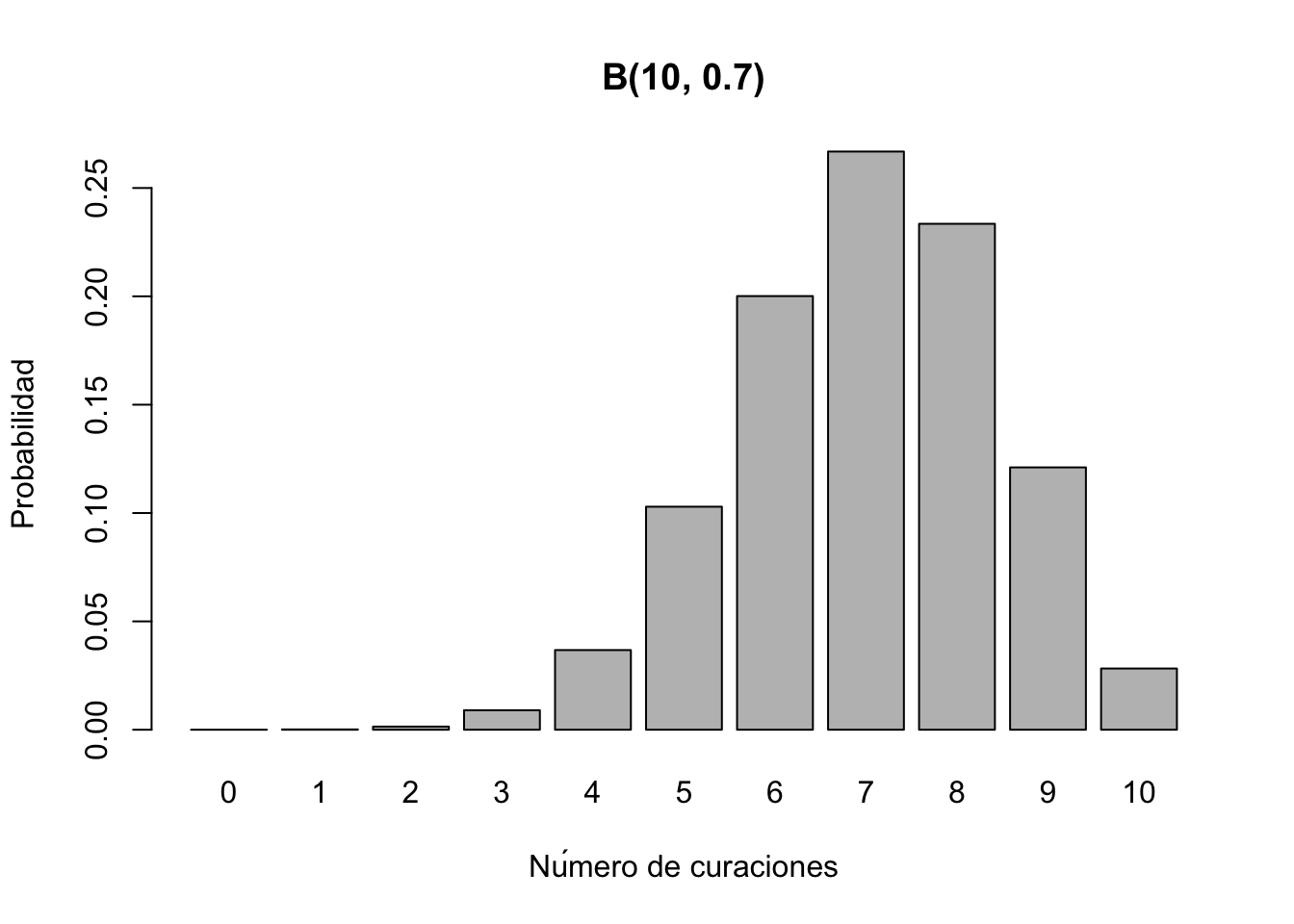
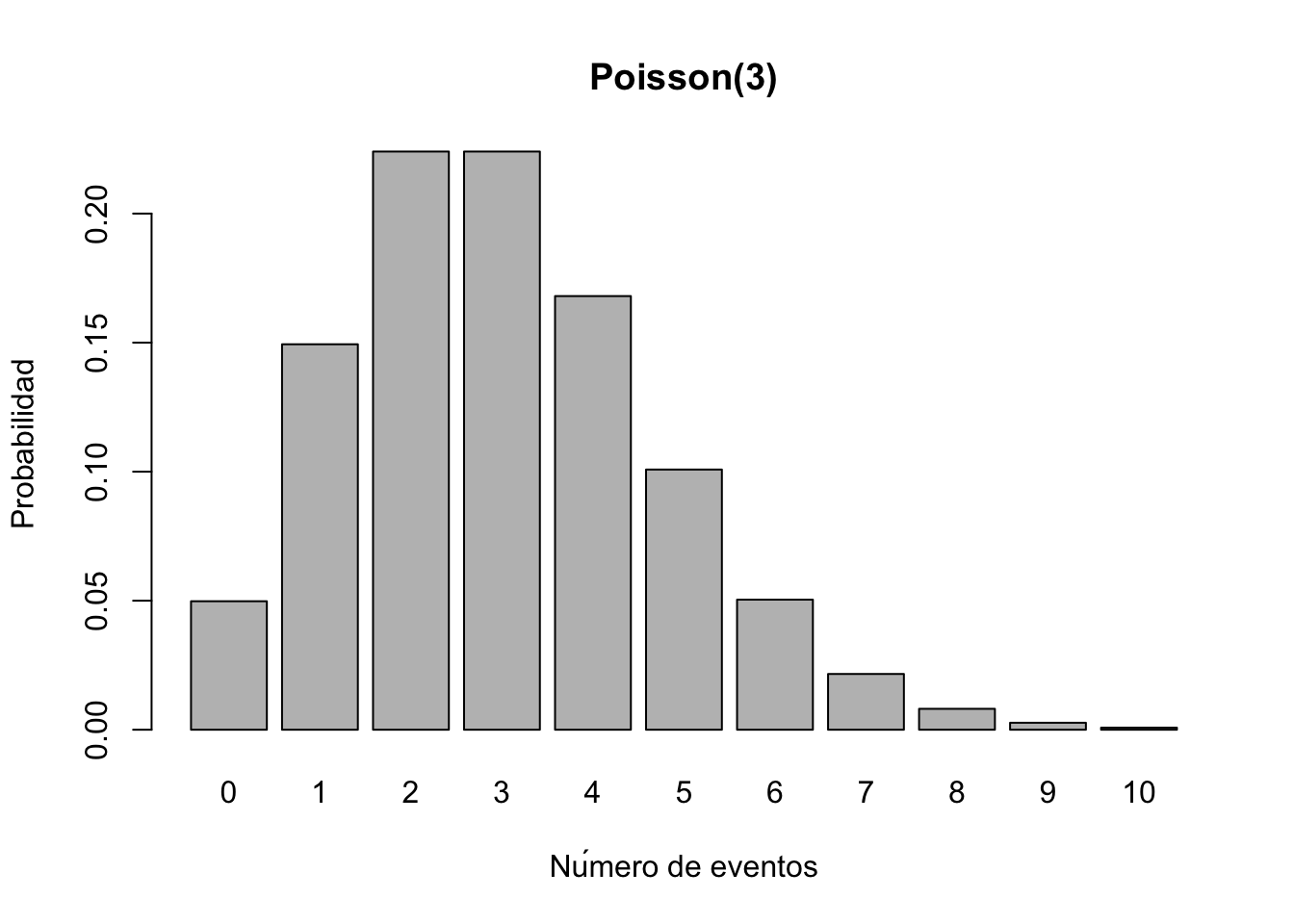
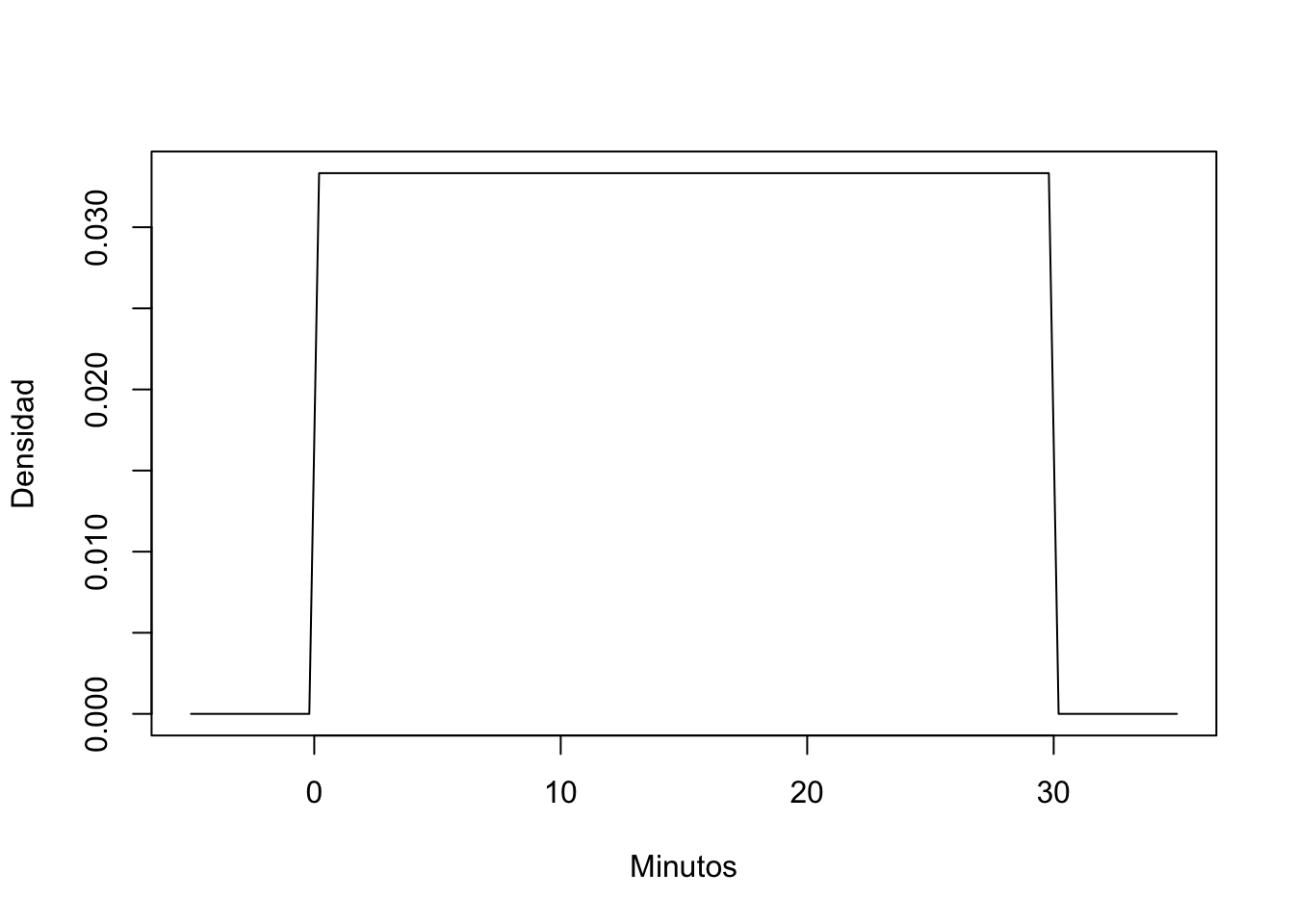
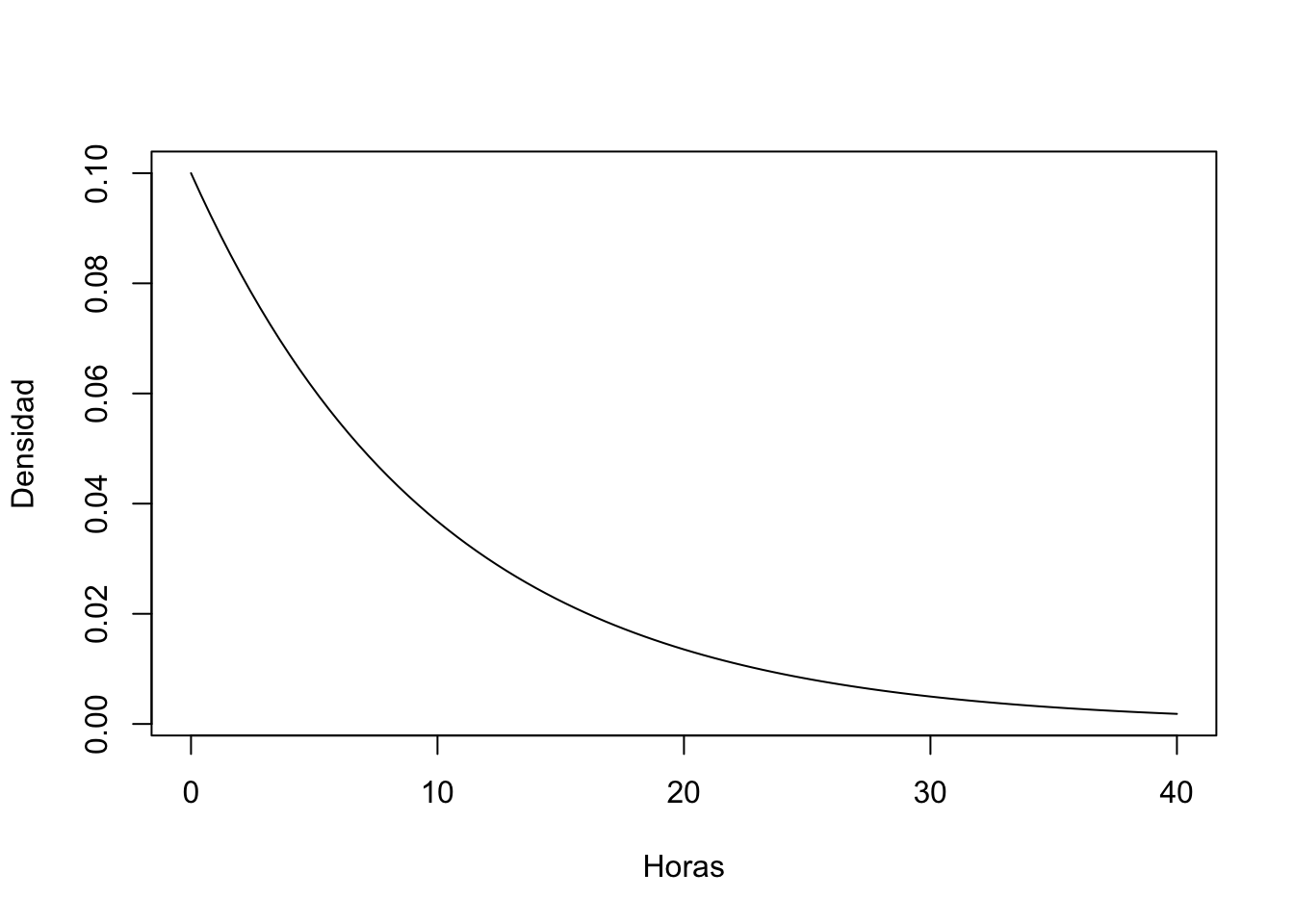
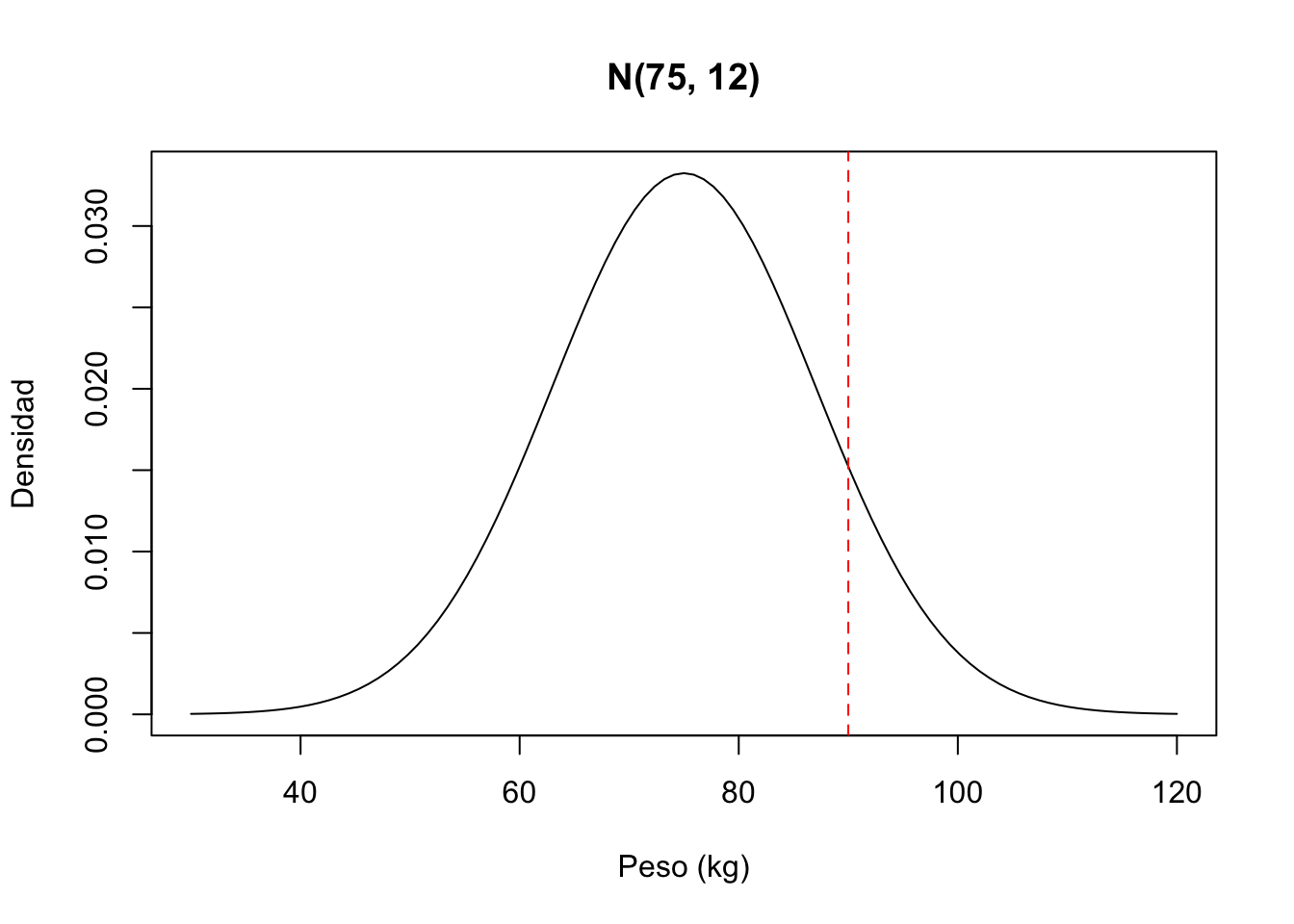
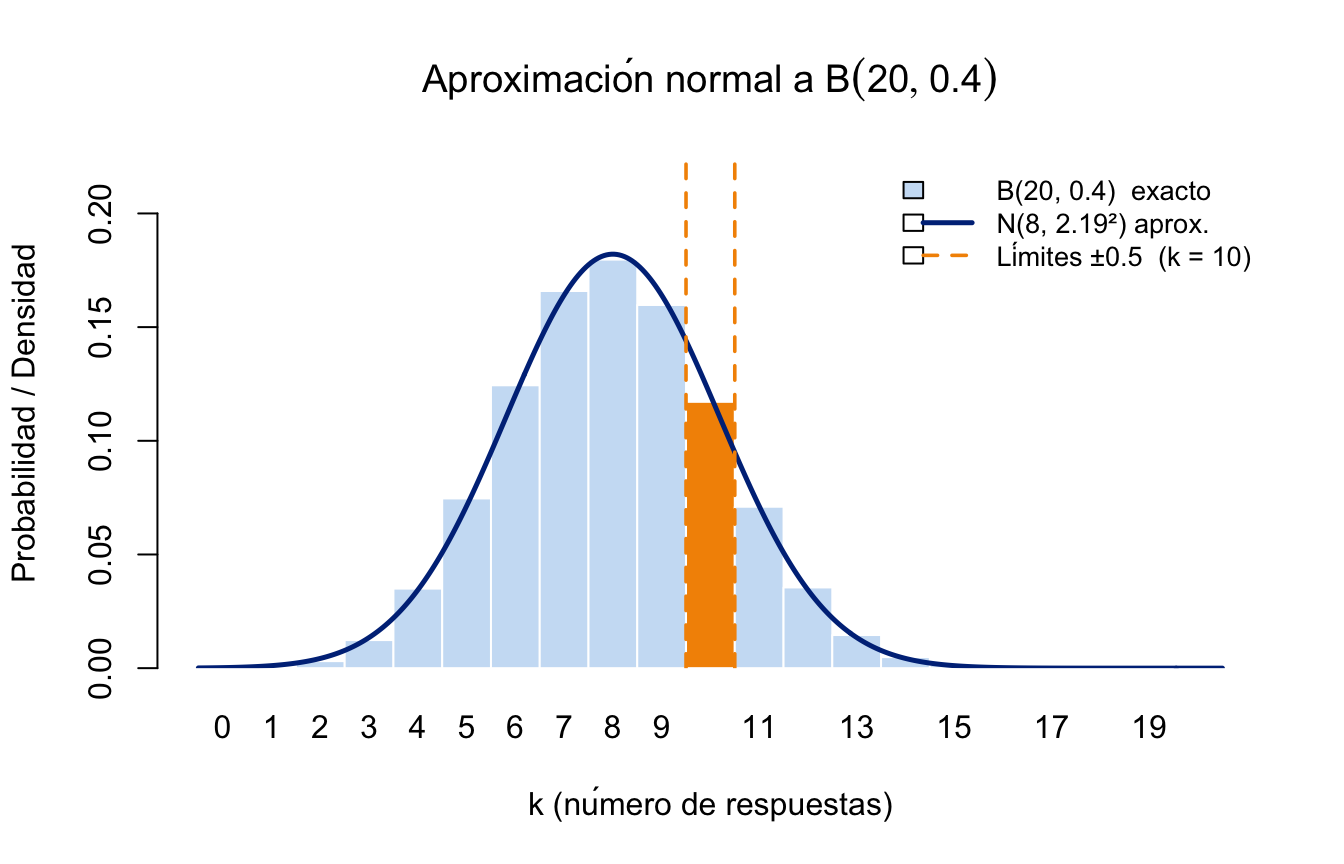
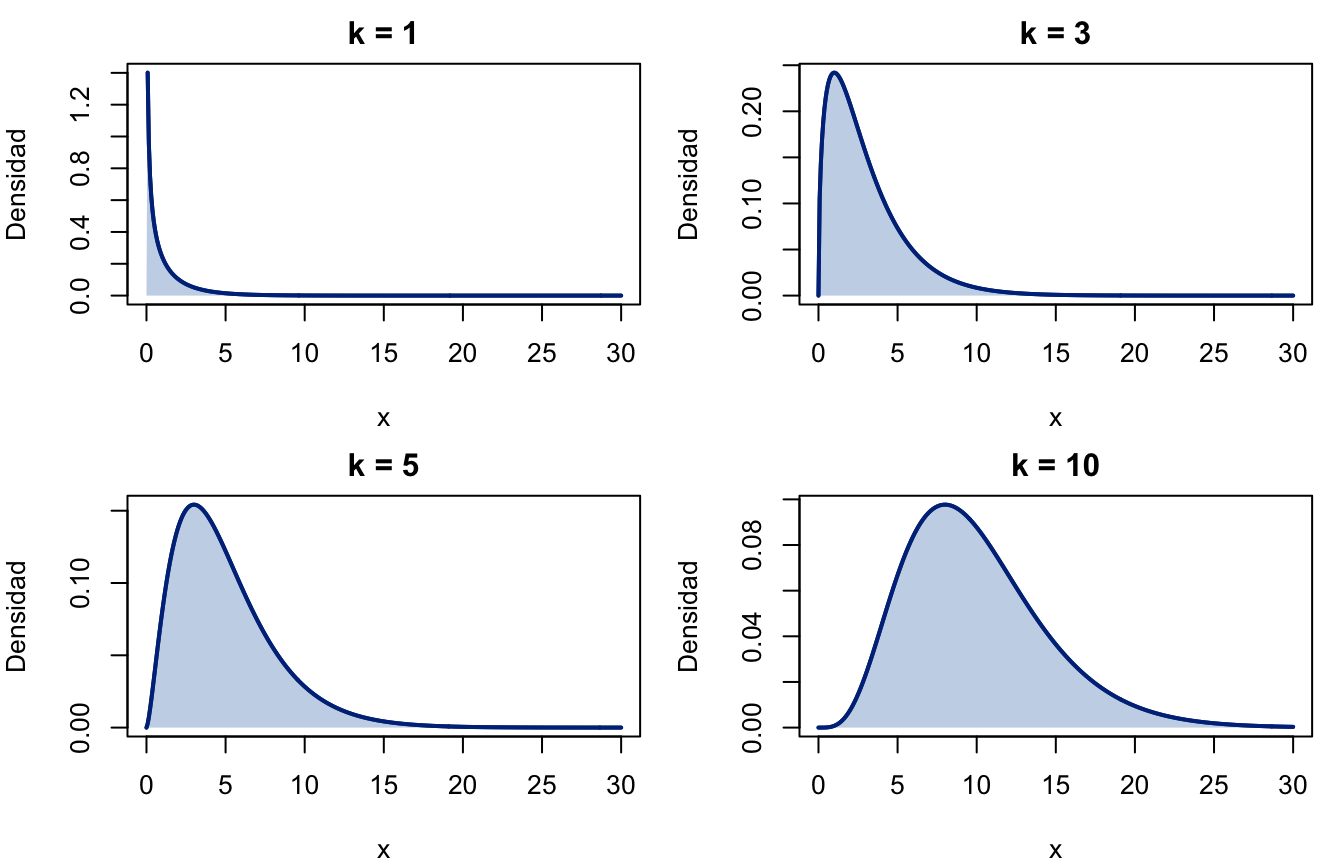
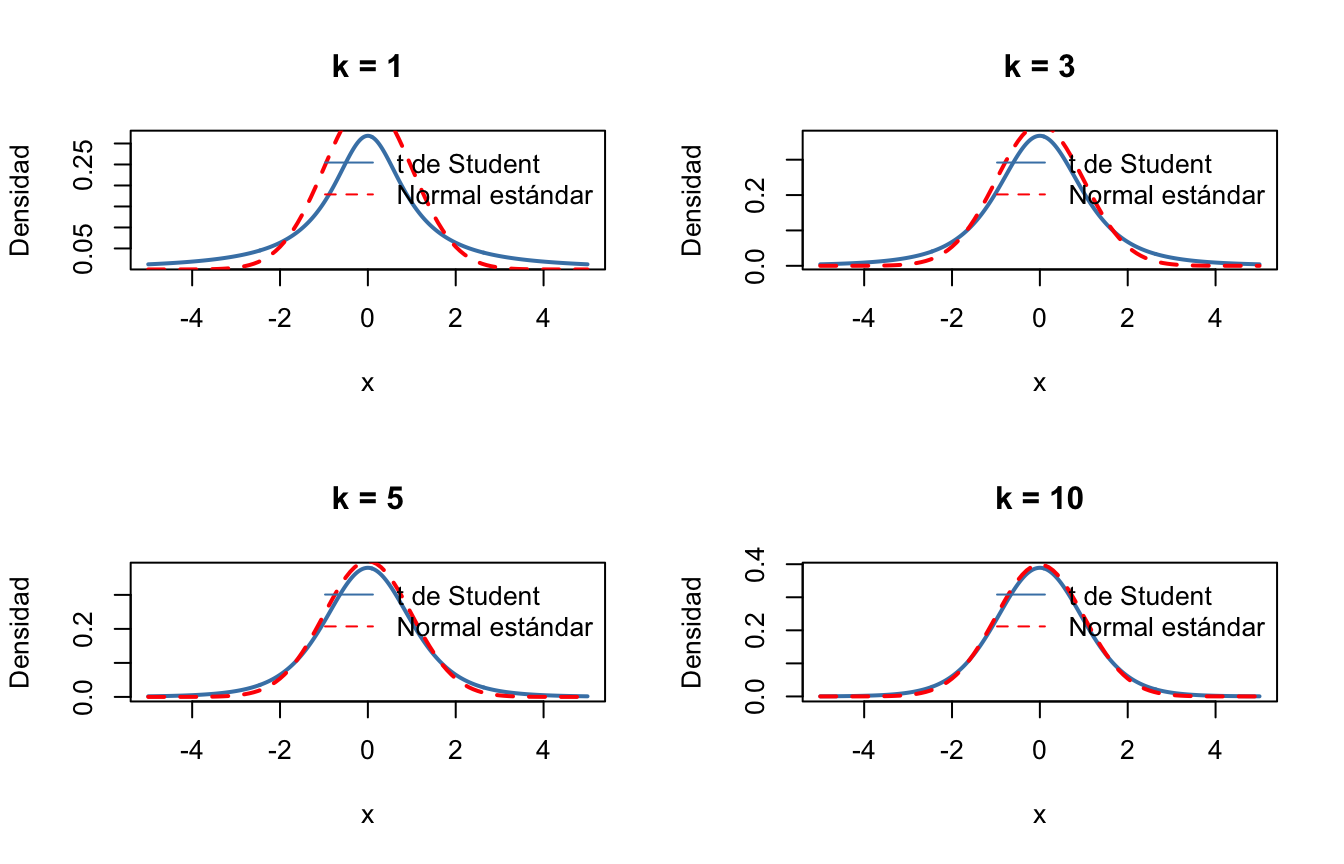
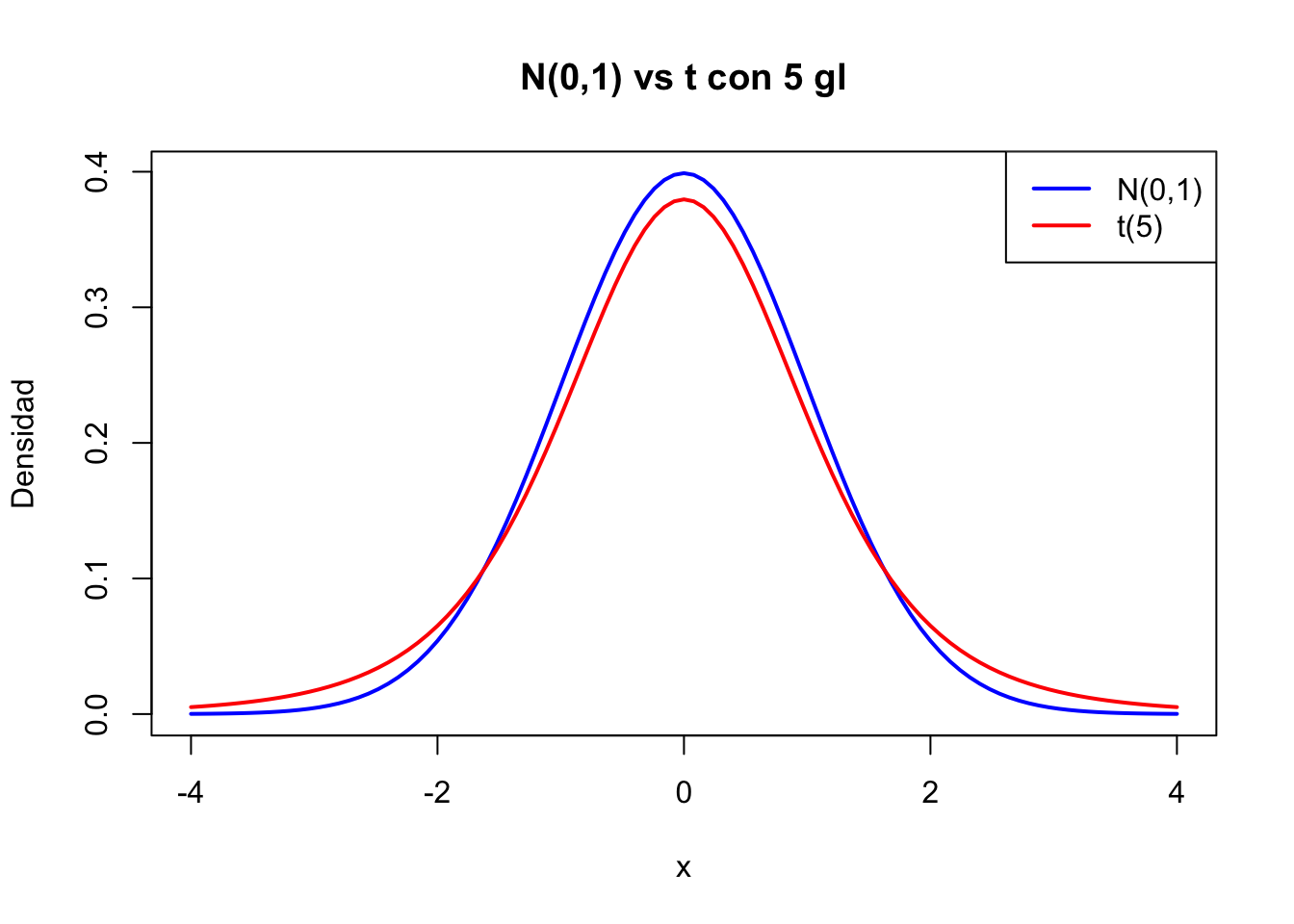
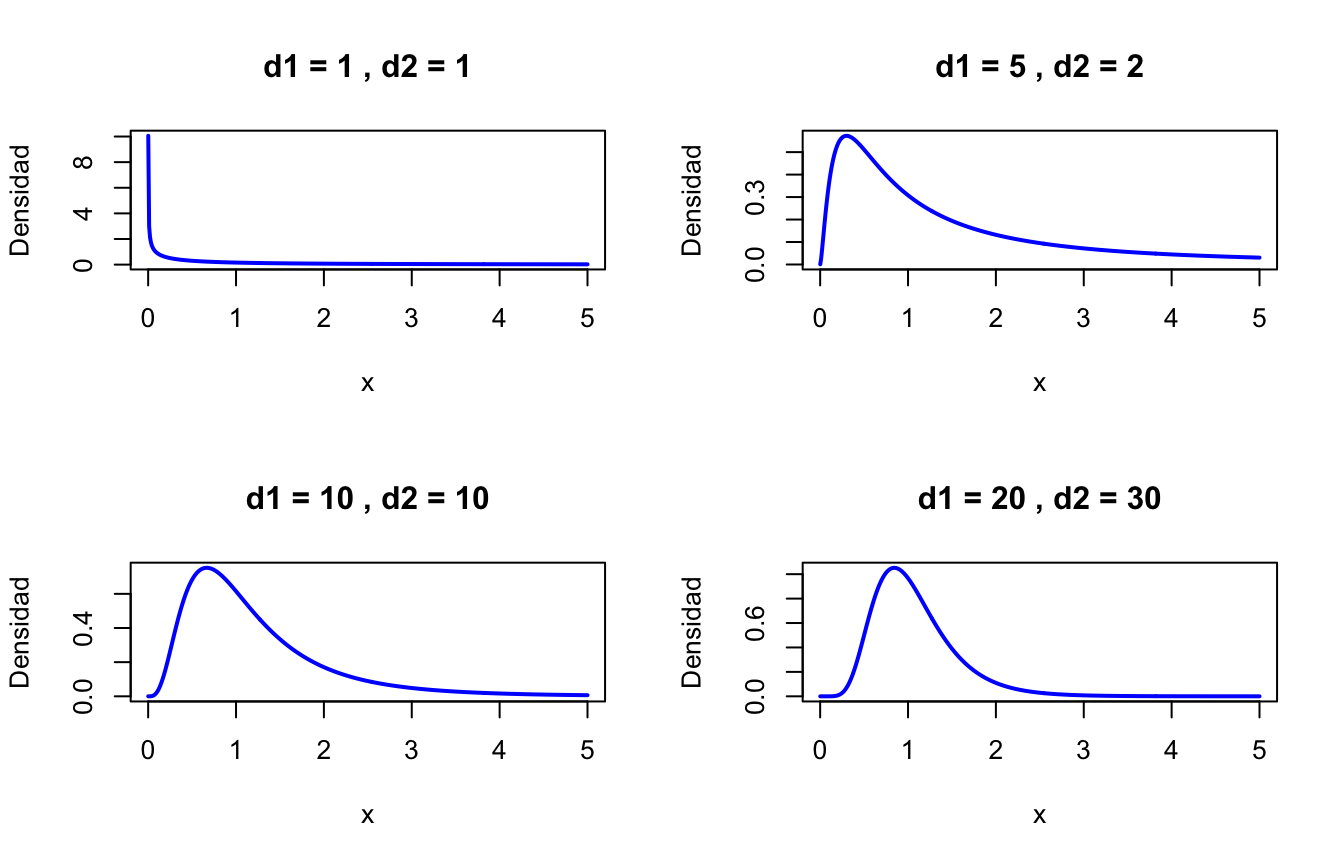
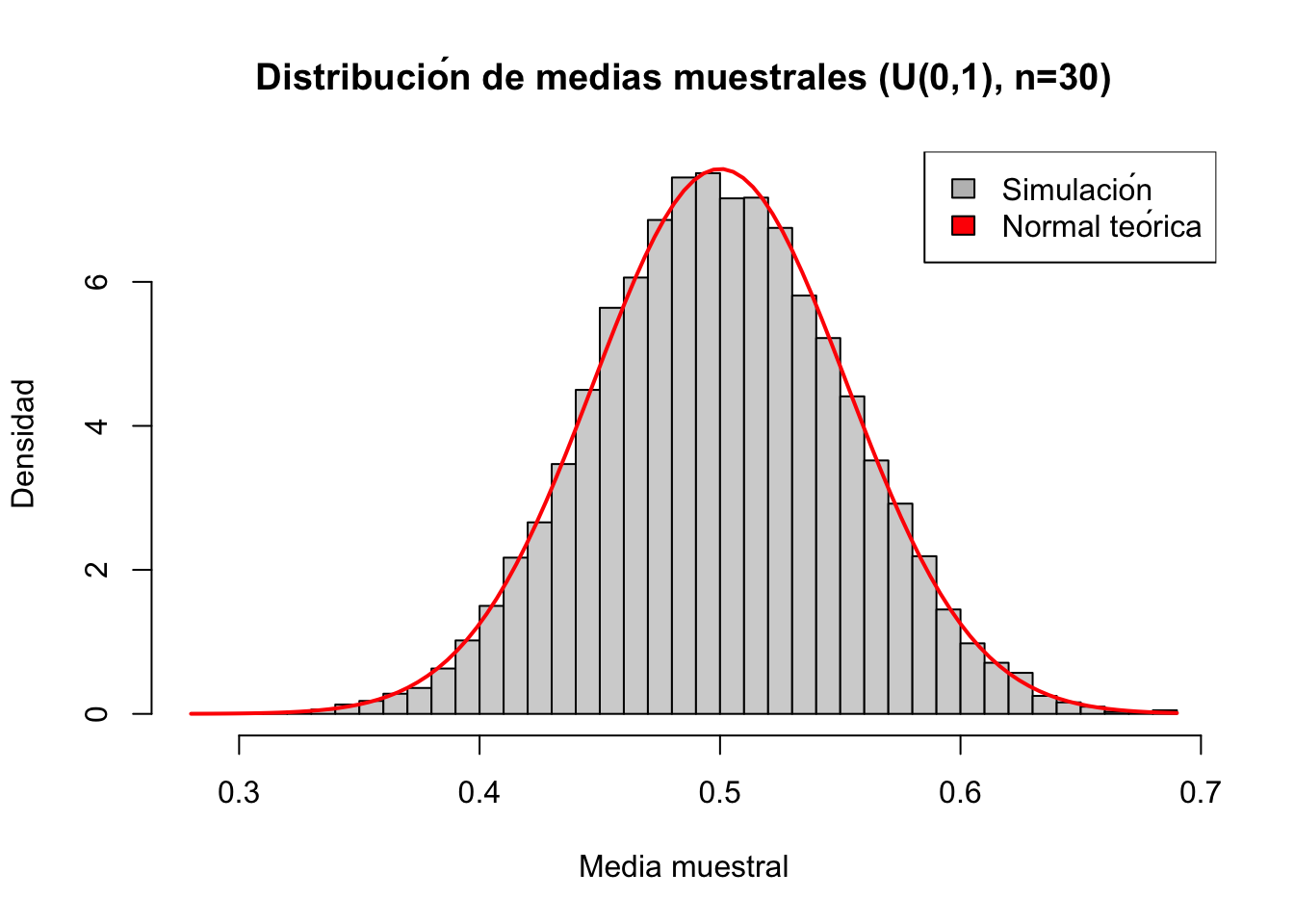
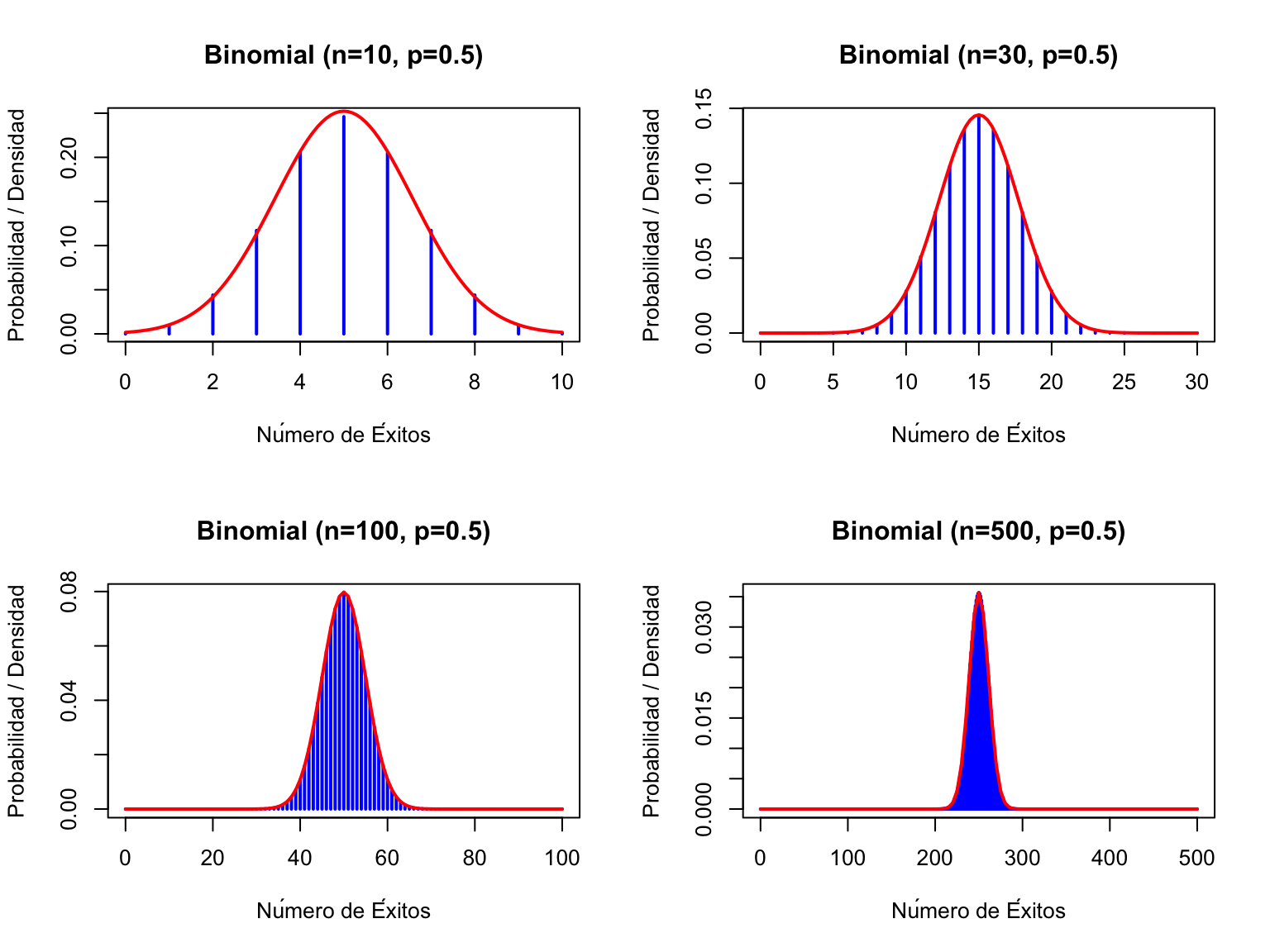
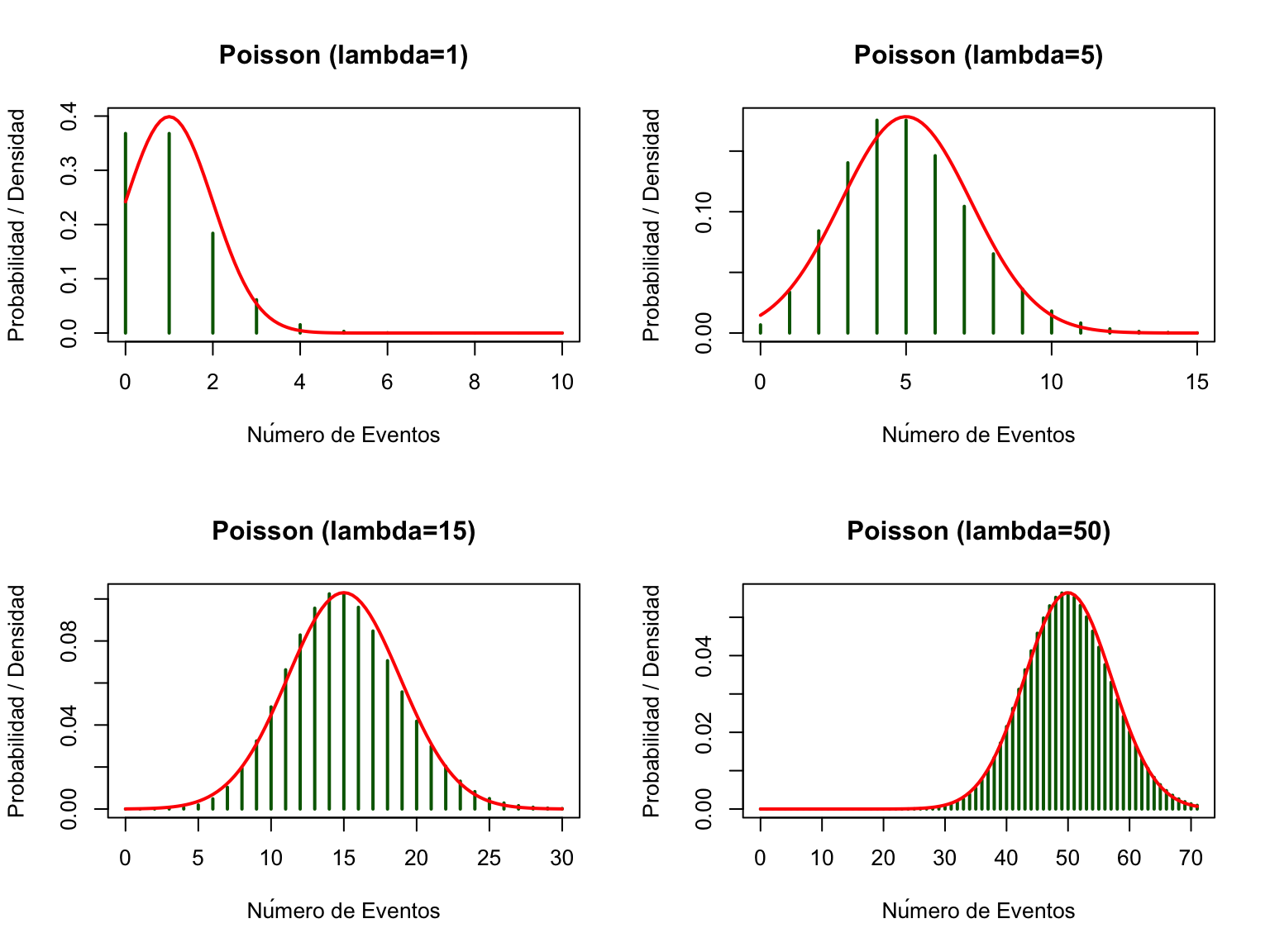
par(mfrow=c(2, 2)) # Organizar 4 gráficos en una cuadrícula de 2x2
# Caso 1: lambda pequeña (lambda=1)
lambda1 <- 1
x1_poisson <- 0:max(10, round(lambda1 + 3 * sqrt(lambda1)))
y1_poisson <- dpois(x1_poisson, lambda=lambda1)
mu1_poisson <- lambda1
sigma1_poisson <- sqrt(lambda1)
plot(x1_poisson, y1_poisson, type="h", lwd=2, col="darkgreen",
main=paste0("Poisson (lambda=", lambda1, ")"),
xlab="Número de Eventos", ylab="Probabilidad / Densidad",
ylim=c(0, max(y1_poisson, dnorm(mu1_poisson, mu1_poisson, sigma1_poisson))))
curve(dnorm(x, mean=mu1_poisson, sd=sigma1_poisson),
from=min(x1_poisson), to=max(x1_poisson), add=TRUE, col="red", lwd=2)
# Caso 2: lambda mediana (lambda=5)
lambda2 <- 5
x2_poisson <- 0:max(15, round(lambda2 + 3 * sqrt(lambda2)))
y2_poisson <- dpois(x2_poisson, lambda=lambda2)
mu2_poisson <- lambda2
sigma2_poisson <- sqrt(lambda2)
plot(x2_poisson, y2_poisson, type="h", lwd=2, col="darkgreen",
main=paste0("Poisson (lambda=", lambda2, ")"),
xlab="Número de Eventos", ylab="Probabilidad / Densidad",
ylim=c(0, max(y2_poisson, dnorm(mu2_poisson, mu2_poisson, sigma2_poisson))))
curve(dnorm(x, mean=mu2_poisson, sd=sigma2_poisson),
from=min(x2_poisson), to=max(x2_poisson), add=TRUE, col="red", lwd=2)
# Caso 3: lambda grande (lambda=15)
lambda3 <- 15
x3_poisson <- 0:max(30, round(lambda3 + 3 * sqrt(lambda3)))
y3_poisson <- dpois(x3_poisson, lambda=lambda3)
mu3_poisson <- lambda3
sigma3_poisson <- sqrt(lambda3)
plot(x3_poisson, y3_poisson, type="h", lwd=2, col="darkgreen",
main=paste0("Poisson (lambda=", lambda3, ")"),
xlab="Número de Eventos", ylab="Probabilidad / Densidad",
ylim=c(0, max(y3_poisson, dnorm(mu3_poisson, mu3_poisson, sigma3_poisson))))
curve(dnorm(x, mean=mu3_poisson, sd=sigma3_poisson),
from=min(x3_poisson), to=max(x3_poisson), add=TRUE, col="red", lwd=2)
# Caso 4: lambda muy grande (lambda=50)
lambda4 <- 50
x4_poisson <- 0:max(70, round(lambda4 + 3 * sqrt(lambda4)))
y4_poisson <- dpois(x4_poisson, lambda=lambda4)
mu4_poisson <- lambda4
sigma4_poisson <- sqrt(lambda4)
plot(x4_poisson, y4_poisson, type="h", lwd=2, col="darkgreen",
main=paste0("Poisson (lambda=", lambda4, ")"),
xlab="Número de Eventos", ylab="Probabilidad / Densidad",
ylim=c(0, max(y4_poisson, dnorm(mu4_poisson, mu4_poisson, sigma4_poisson))))
curve(dnorm(x, mean=mu4_poisson, sd=sigma4_poisson),
from=min(x4_poisson), to=max(x4_poisson), add=TRUE, col="red", lwd=2)