Test de student con una y dos muestras (independientes o apareadas)
testt.Rdt-test con una y dos muestras, independientes o relacionadas (se han omitido acentos deliberadamente por la incompatibilidad de caracteres de texto)
Usage
testt(
m = NULL,
m1 = NULL,
m2 = NULL,
n = 0,
n1 = 0,
n2 = 0,
s = 0,
s1 = 0,
s2 = 0,
par = FALSE,
m0 = 0,
grupos = NULL,
conf = 0.95,
vac = TRUE,
alfa = 0.05,
delta = 0,
potencia = 0.8,
beta = 0.2,
decs = 3,
grf = TRUE
)Arguments
- m
vector o valor real: vector de datos cuando se indica una muestra o la variable a analizar en el caso de muestras independientes. Media de la variable a analizar, previamente calculada, cuando se indica una sola muestra con la informacion resumida
- m1
vector o valor real: vector de datos de la primera muestra cuando se indican dos muestras apareadas. El contraste sera Media(m1)-Media(m2)=m0, o medias muestrales cuando se indican dos muestras independientes con las medidas de sintesis
- m2
vector o valor real: vector de datos de la segunda muestra cuando se indican dos muestras apareadas. El contraste sera Media(m1)-Media(m2)=m0, o medias muestrales cuando se indican dos muestras independientes con las medidas de sintesis
- n
valor entero: tamano muestral cuando se indican los datos resumidos de una sola muestra
- n1
valor entero: tamano de la muestra 1 cuando se indican los datos resumidos de dos muestras independientes,
- n2
valor entero: tamano de la muestra 2 cuando se indican los datos resumidos de dos muestras independientes
- s
valor real: desviacion tipica de la variable en el test con una muestra.
- s1
valor real: desviacion tipica de las muestras 1 para la comparacion de 2 muestras independientes especificadas por sus medidas de sintesis.
- s2
valor real: desviacion tipica de las muestras 2 para la comparacion de 2 muestras independientes especificadas por sus medidas de sintesis.
- par
valor logico: si los tamanos de m1 y m2 son iguales se asumen muestras apareadas, pero si par=FALSE se asumen independientes
- m0
valor real: valor a contrastar en el test de una muestra o magnitud de la diferencia (efecto bruto) en los test con dos muestras
- grupos
variable binaria o factor con dos niveles: variable de agrupacion en la comparacion de dos muestras independientes especificadas con los datos individuales de cada caso
- conf
valor real < 1: nivel de confianza para la elaboracion del IC para la estimacion de la media o del tamaño del efecto
- vac
valor logico: TRUE=se trata de una variable aleatoria continua; FALSE= la variable es discreta y se aplica cpc_ Por defecto = TRUE.
- alfa
valor real < 1: error alfa (parametro alternativamente al nivel de confianza, en tanto por uno). Por defecto =.05.
- delta
valor real: tamano del efecto a detectar, es decir, a declarar significativo con la potencia deseada
- potencia
valor real <1: potencia deseada para estudiar la fiabilidad de la decision por la hipotesis nula y el tamaño de muestra.
- beta
valor real: error de tipo II, parametro alternativo a la potencia
- decs
valor entero: precision decimal para la salida de resultados. Por defecto = 4.
- grf
valor logico: Si TRUE/FALSE se genera/omite la salida grafica
Value
Informe con medidas descriptivas, test de normalidad (si se aportan datos individuales), test del cociente de varianzas de Fisher (si procede), t-test con estimacion del tamano del efecto bruto, estudio de la potencia y estimacion de tamano muestral.
Examples
# [A] Test con una muestra
# [A.1] Con los datos individuales
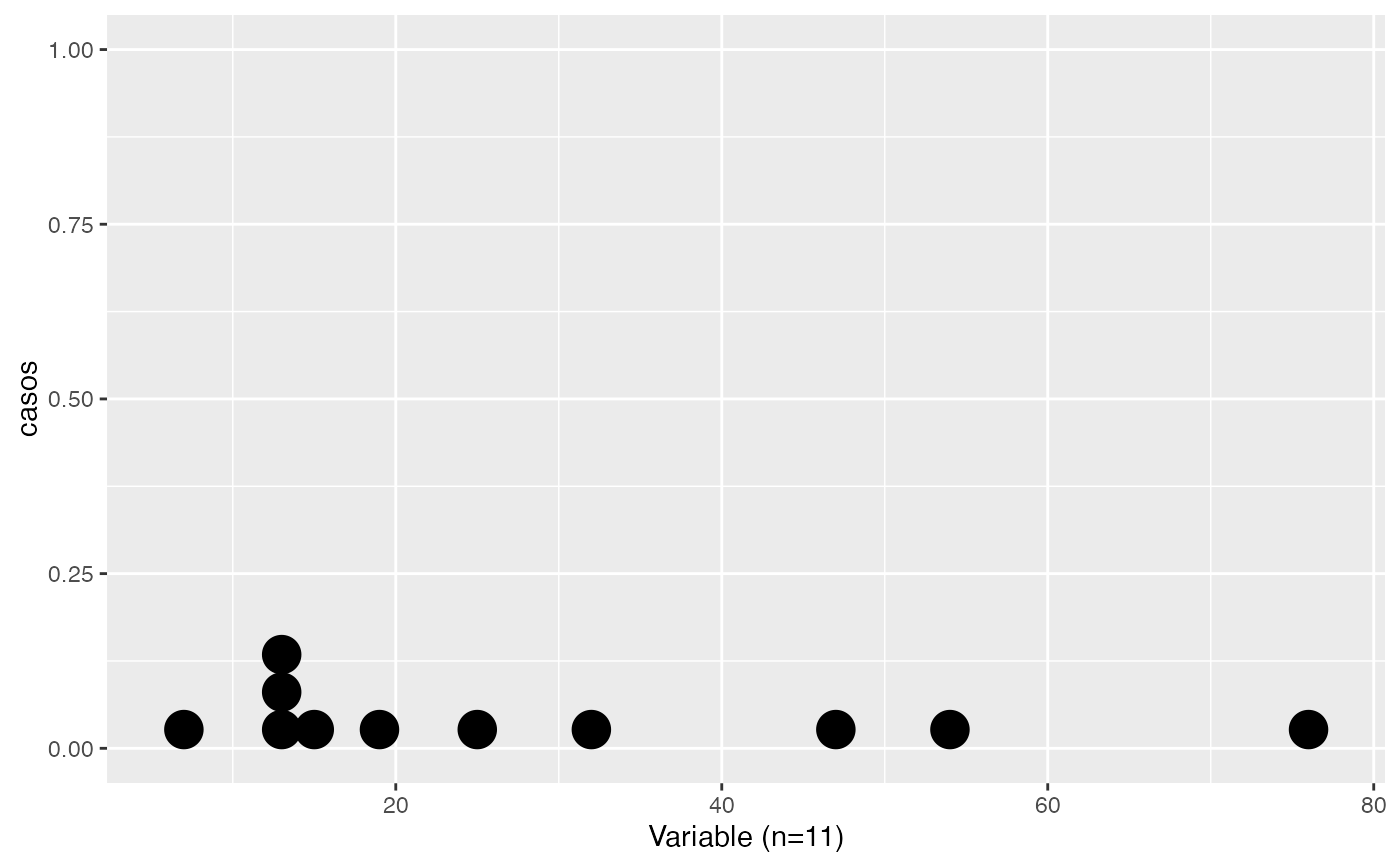
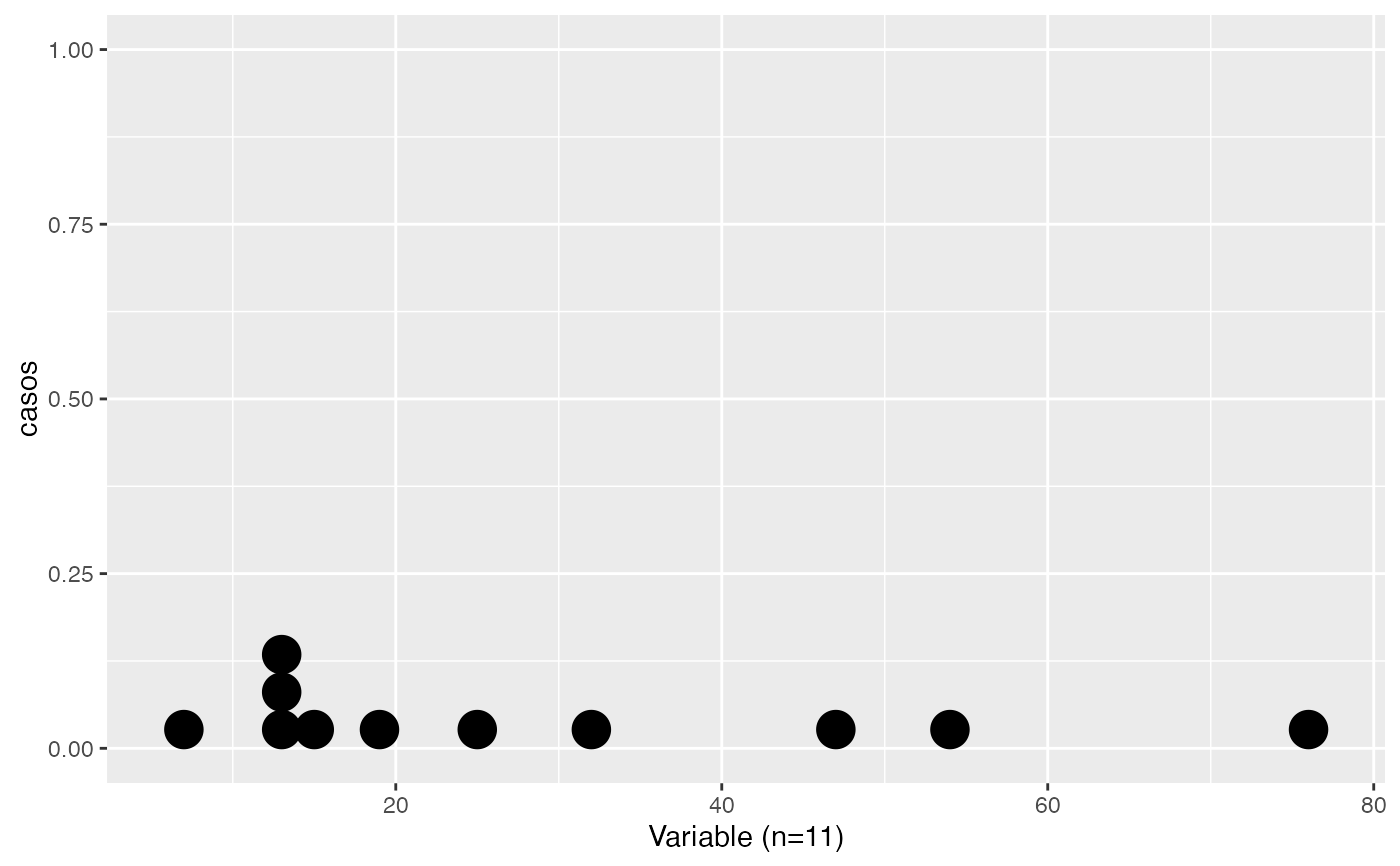
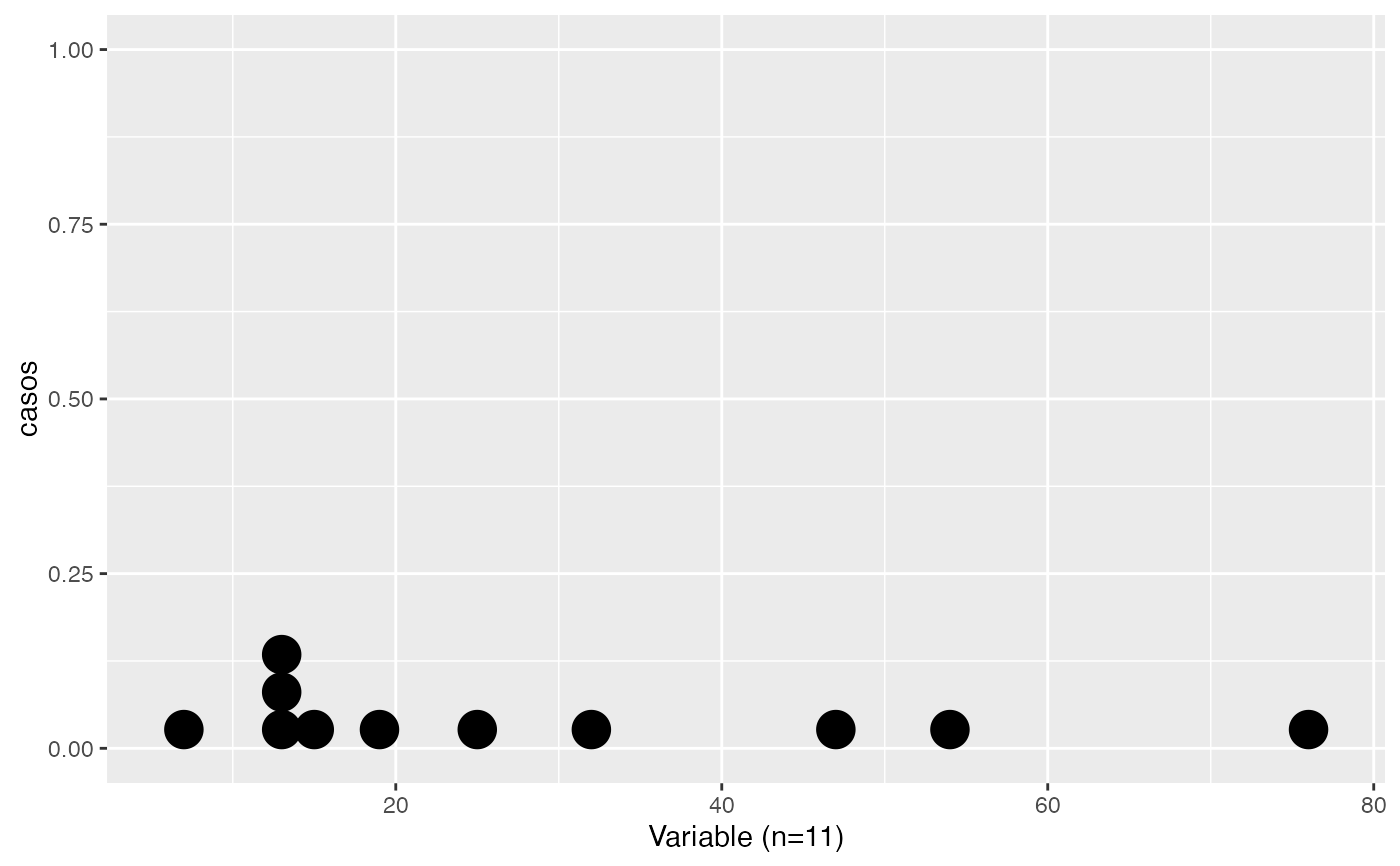
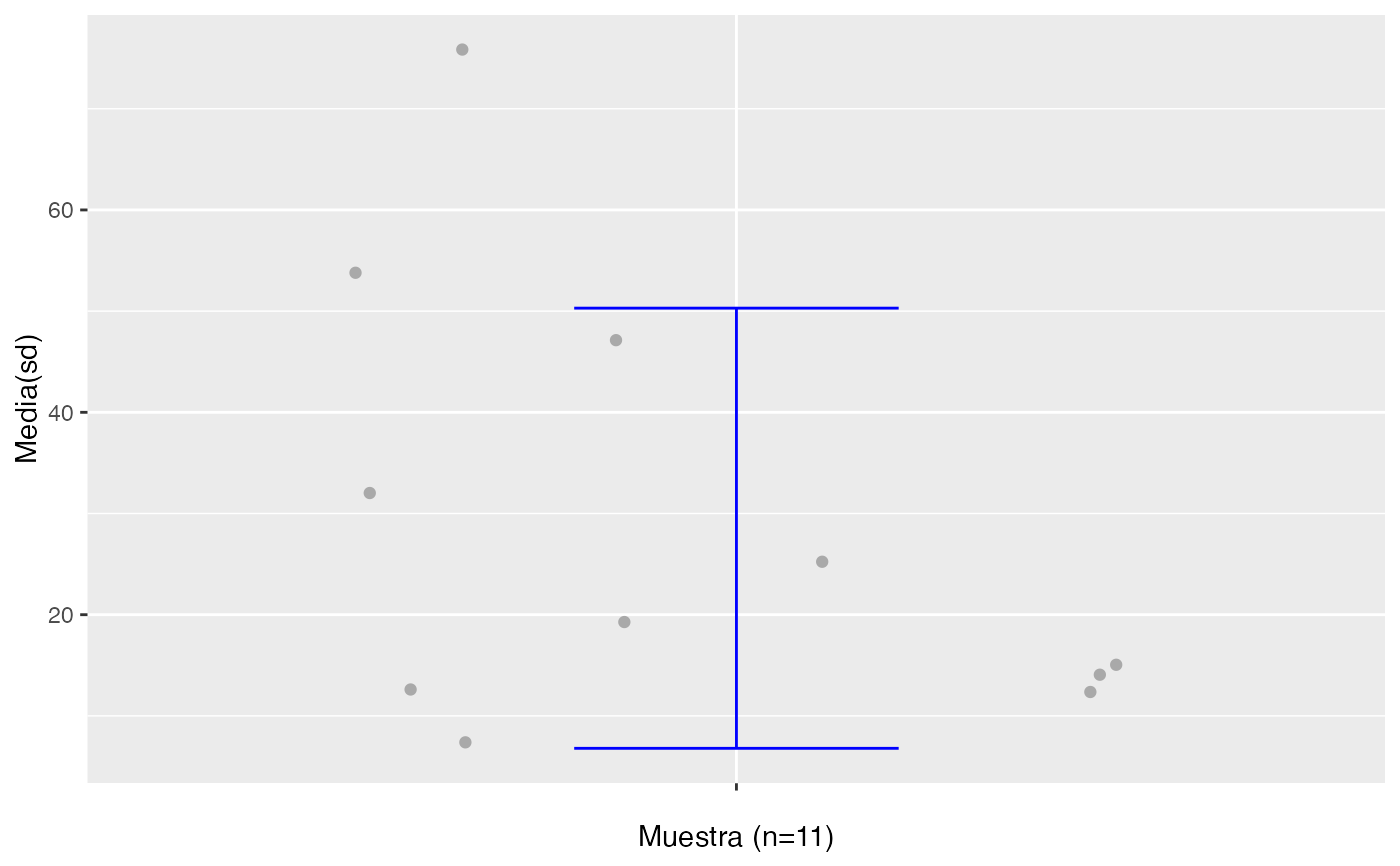
datos<-c(76,54,12,47,13,15,25,14,19,32,7)
testt(m=datos, m0=25)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'datos'
#> n = 11.000
#> media = 28.545
#> d.t. = 21.750
#> sem = 6.558
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (13.933, 43.157)
#>
#> # Test de normalidad de Shapiro-Wilk:
#> W = 0.853, gl = 11, p = 0.047
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=25.000
#> texp = 0.541, gl = 10
#> p = 0.601 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.300 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-11.067, 18.157)
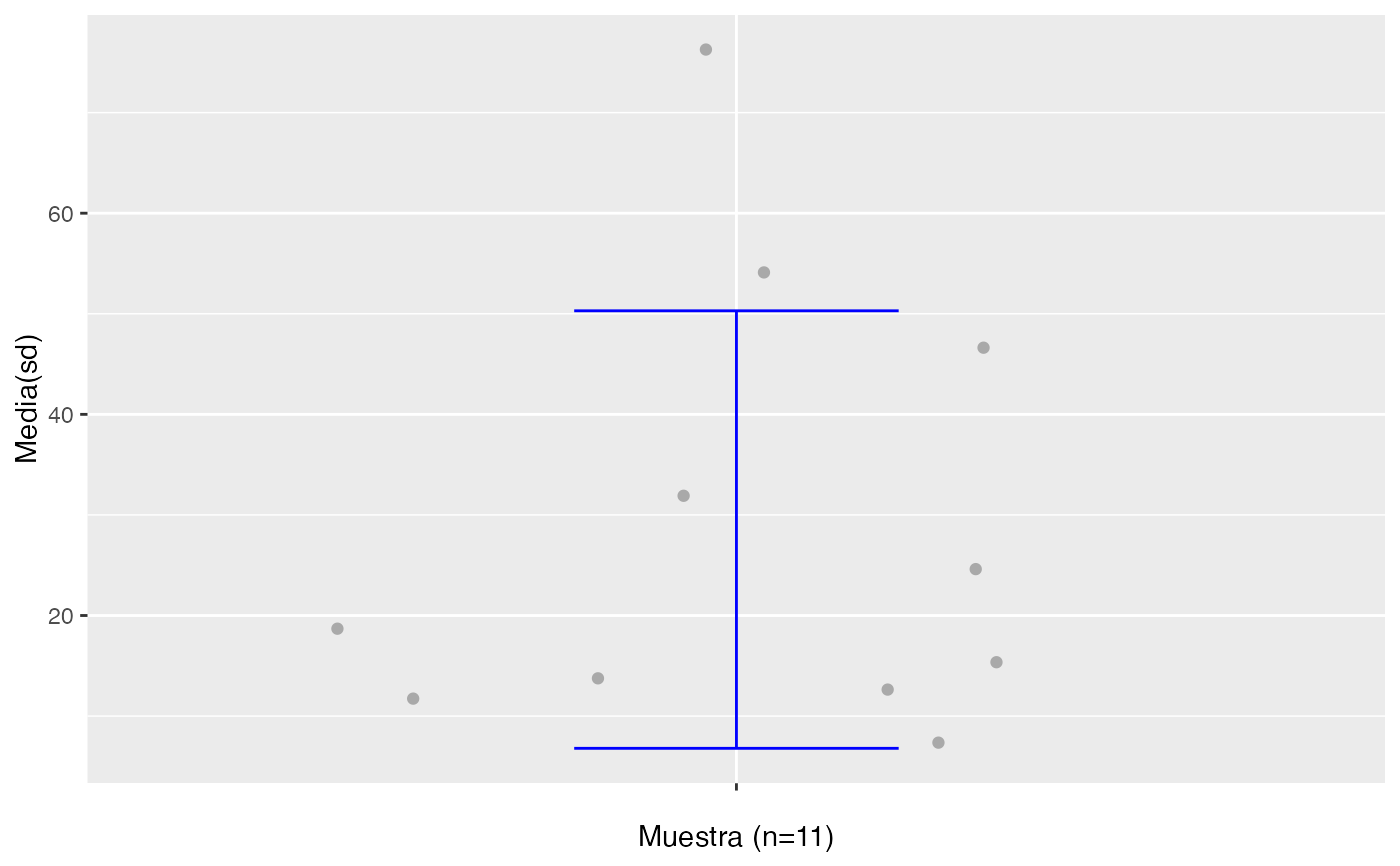 testt(m=datos, m0=29,delta=3)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'datos'
#> n = 11.000
#> media = 28.545
#> d.t. = 21.750
#> sem = 6.558
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (13.933, 43.157)
#>
#> # Test de normalidad de Shapiro-Wilk:
#> W = 0.853, gl = 11, p = 0.047
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=29.000
#> texp = 0.069, gl = 10
#> p = 0.946 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.473 para la alternativa unilateral H₁:μ<μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-15.067, 14.157)
#>
#> # Estudio de la potencia: δ = 3 -> [26, 32], potencia θ = 80%
#> 60%-IC(μ-μ₀) = (-6.219, 5.310) con μ₀ = 29.000
#> 60%-IC(μ) = (22.781, 34.310)
#>
#> -(-[---|---]-)-- potencia < 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.8
#> Error de tipo I: α = 0.05
#> n ⩾ 508 casos
#>
testt(m=datos, m0=29,delta=3)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'datos'
#> n = 11.000
#> media = 28.545
#> d.t. = 21.750
#> sem = 6.558
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (13.933, 43.157)
#>
#> # Test de normalidad de Shapiro-Wilk:
#> W = 0.853, gl = 11, p = 0.047
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=29.000
#> texp = 0.069, gl = 10
#> p = 0.946 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.473 para la alternativa unilateral H₁:μ<μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-15.067, 14.157)
#>
#> # Estudio de la potencia: δ = 3 -> [26, 32], potencia θ = 80%
#> 60%-IC(μ-μ₀) = (-6.219, 5.310) con μ₀ = 29.000
#> 60%-IC(μ) = (22.781, 34.310)
#>
#> -(-[---|---]-)-- potencia < 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.8
#> Error de tipo I: α = 0.05
#> n ⩾ 508 casos
#>
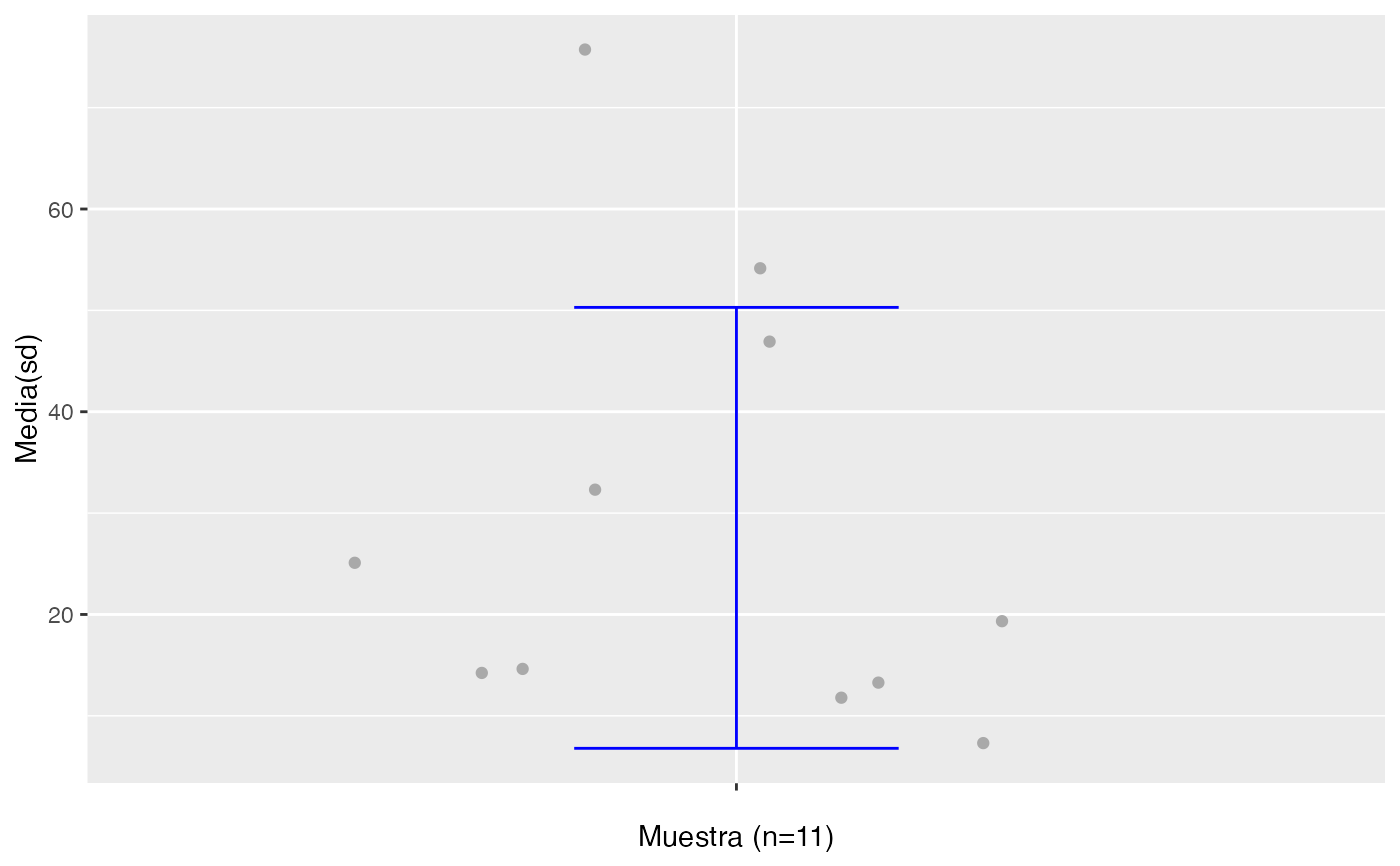 testt(m=datos, m0=29,delta=3,vac=FALSE)
#>
#> # t-Test con una muestra
#> # ----------------------
#> Se aplica corrección por continuidad (cpc) sobre el t-test y los intervalos
#>
#> # Resumen de 'datos'
#> n = 11.000
#> media = 28.545
#> d.t. = 21.750
#> sem = 6.558
#> cpc = 0.045
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (13.888, 43.203)
#>
#> # Test de normalidad de Shapiro-Wilk:
#> W = 0.853, gl = 11, p = 0.047
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=29.000
#> texp = 0.062, gl = 10
#> p = 0.951 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.476 para la alternativa unilateral H₁:μ<μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-15.067, 14.157)
#>
#> # Estudio de la potencia: δ = 3 -> [26, 32], potencia θ = 80%
#> 60%-IC(μ-μ₀) = (-6.219, 5.310) con μ₀ = 29.000
#> 60%-IC(μ) = (22.781, 34.310)
#>
#> -(-[---|---]-)-- potencia < 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.8
#> Error de tipo I: α = 0.05
#> n ⩾ 508 casos
#>
testt(m=datos, m0=29,delta=3,vac=FALSE)
#>
#> # t-Test con una muestra
#> # ----------------------
#> Se aplica corrección por continuidad (cpc) sobre el t-test y los intervalos
#>
#> # Resumen de 'datos'
#> n = 11.000
#> media = 28.545
#> d.t. = 21.750
#> sem = 6.558
#> cpc = 0.045
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (13.888, 43.203)
#>
#> # Test de normalidad de Shapiro-Wilk:
#> W = 0.853, gl = 11, p = 0.047
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=29.000
#> texp = 0.062, gl = 10
#> p = 0.951 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.476 para la alternativa unilateral H₁:μ<μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-15.067, 14.157)
#>
#> # Estudio de la potencia: δ = 3 -> [26, 32], potencia θ = 80%
#> 60%-IC(μ-μ₀) = (-6.219, 5.310) con μ₀ = 29.000
#> 60%-IC(μ) = (22.781, 34.310)
#>
#> -(-[---|---]-)-- potencia < 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.8
#> Error de tipo I: α = 0.05
#> n ⩾ 508 casos
#>
 # [A.2] Con informacion muestral sintetizada
testt(m=37, s=5, n=158, m0=25)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 158.000
#> media = 37.000
#> d.t. = 5.000
#> sem = 0.398
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (36.214, 37.786)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=25.000
#> texp = 30.168, gl = 157
#> p < 0.001 para la alternativa bilateral H₁:μ≠μ₀
#> p < 0.001 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (11.214, 12.786)
testt(m=37, s=7, n=158, m0=36,delta=3,potencia=0.95)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 158.000
#> media = 37.000
#> d.t. = 7.000
#> sem = 0.557
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (35.900, 38.100)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=36.000
#> texp = 1.796, gl = 157
#> p = 0.074 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.037 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-0.100, 2.100)
#>
#> # Estudio de la potencia: δ = 3 -> [33, 39], potencia θ = 95%
#> 90%-IC(μ-μ₀) = (0.079, 1.921) con μ₀ = 36.000
#> 90%-IC(μ) = (36.079, 37.921)
#>
#> ---[--|(-)-]---- potencia > 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.95
#> Error de tipo I: α = 0.05
#> n ⩾ 72 casos
#>
# [B] Test con dos muestras independientes
# [B.1] 2 muestras independientes con datos individuales
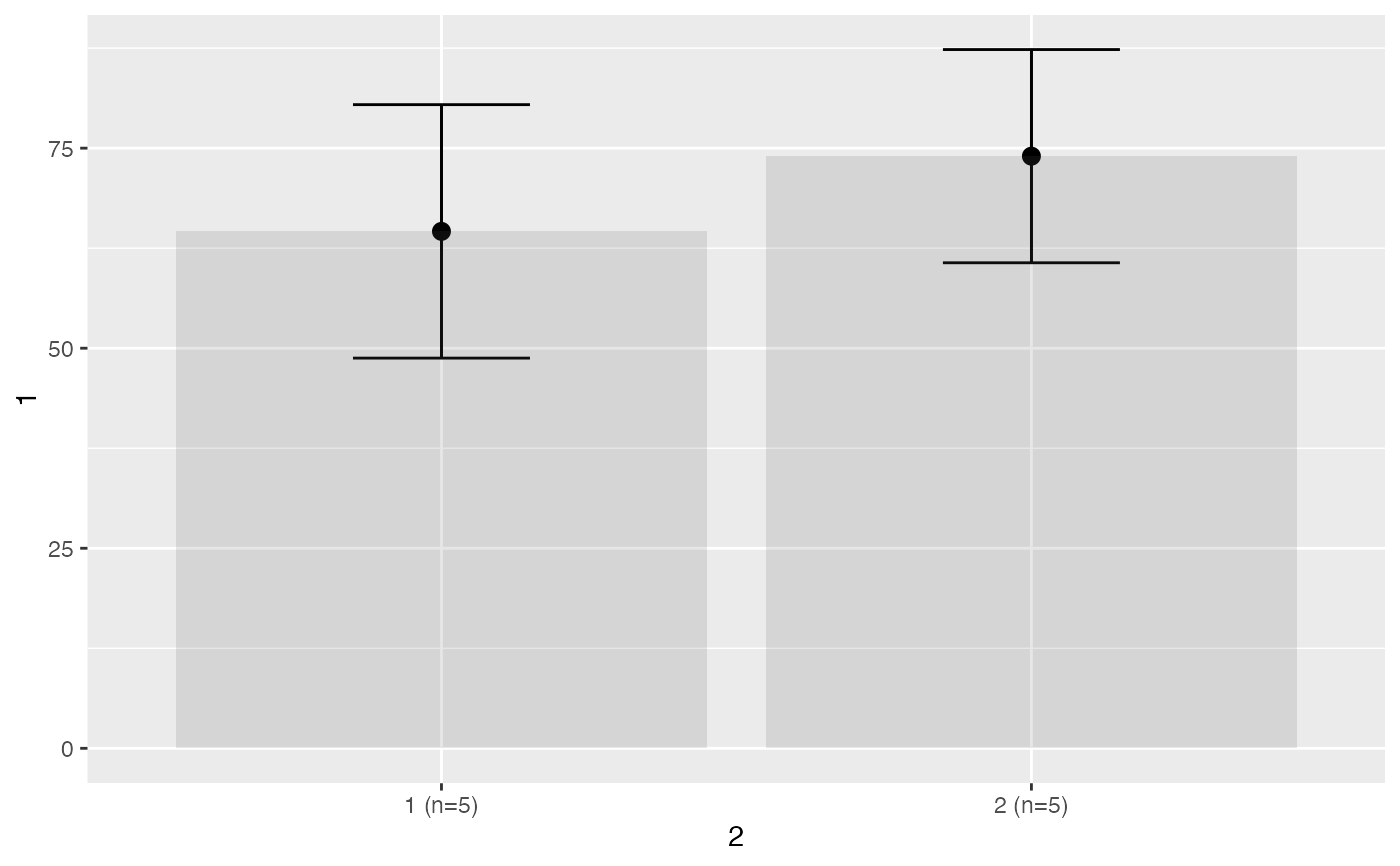
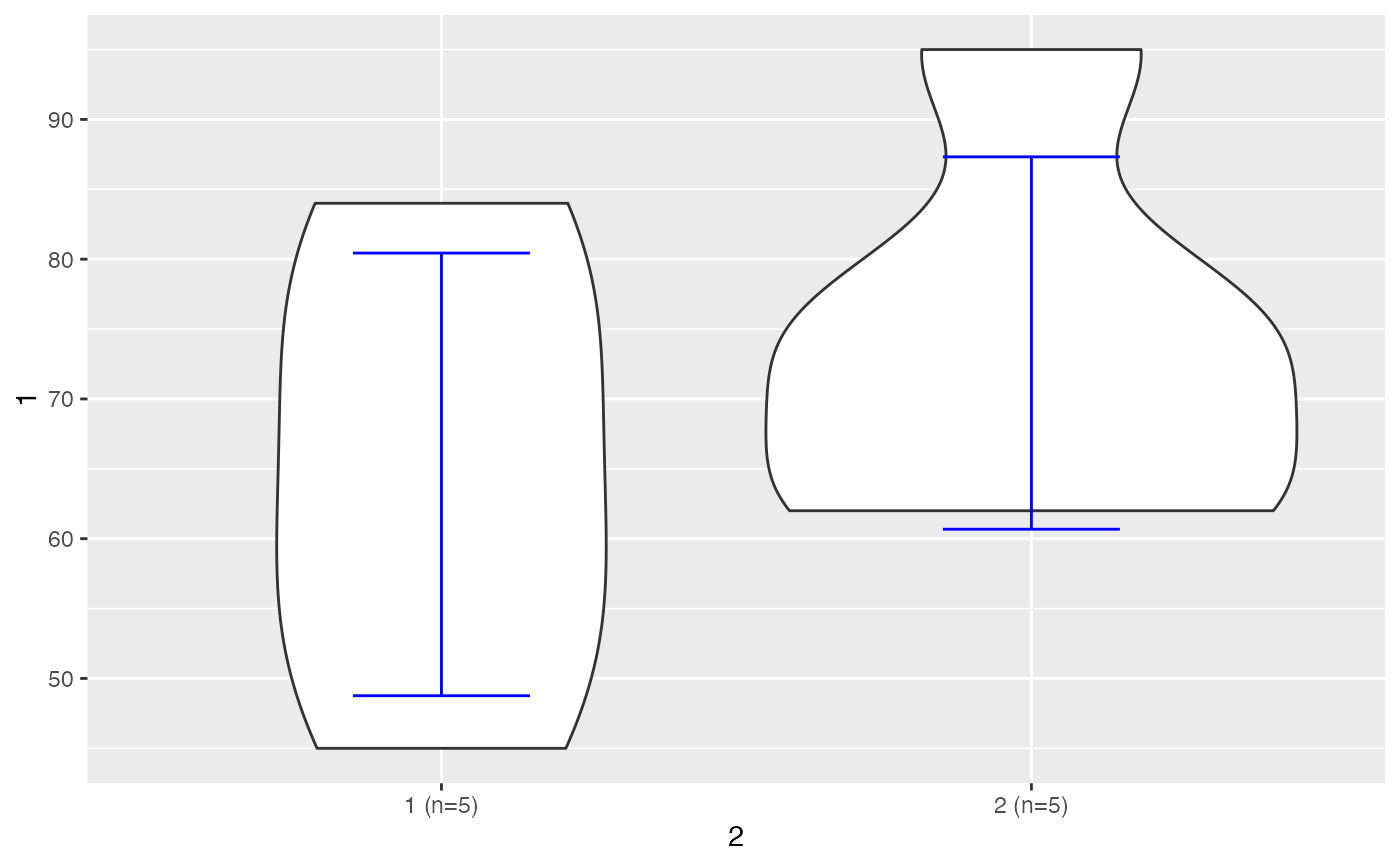
sexo<-c( 1,2,2,2,1,1,2,2,1,1)
peso<-c(54,64,76,84,45,74,76,95,63,62)
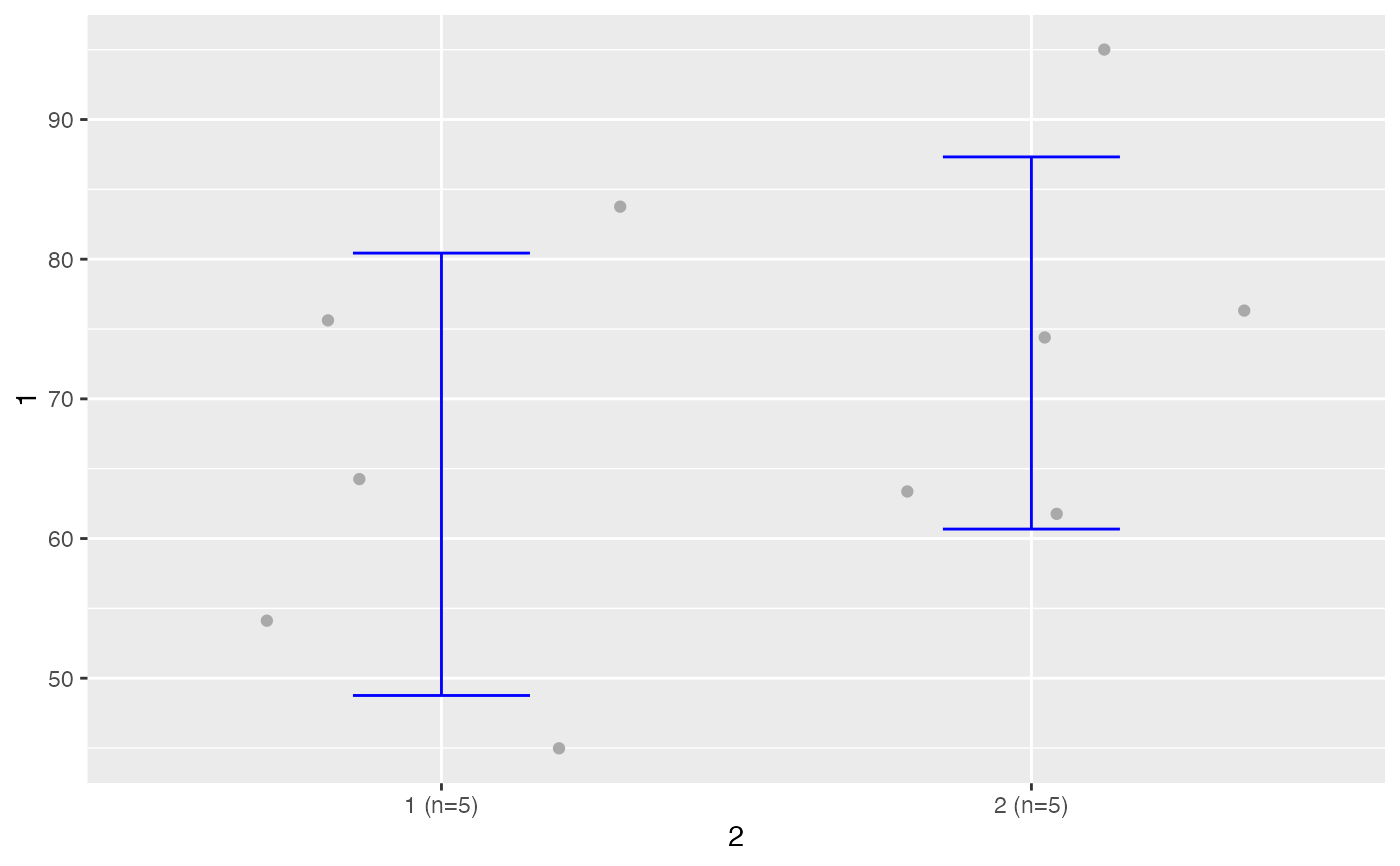
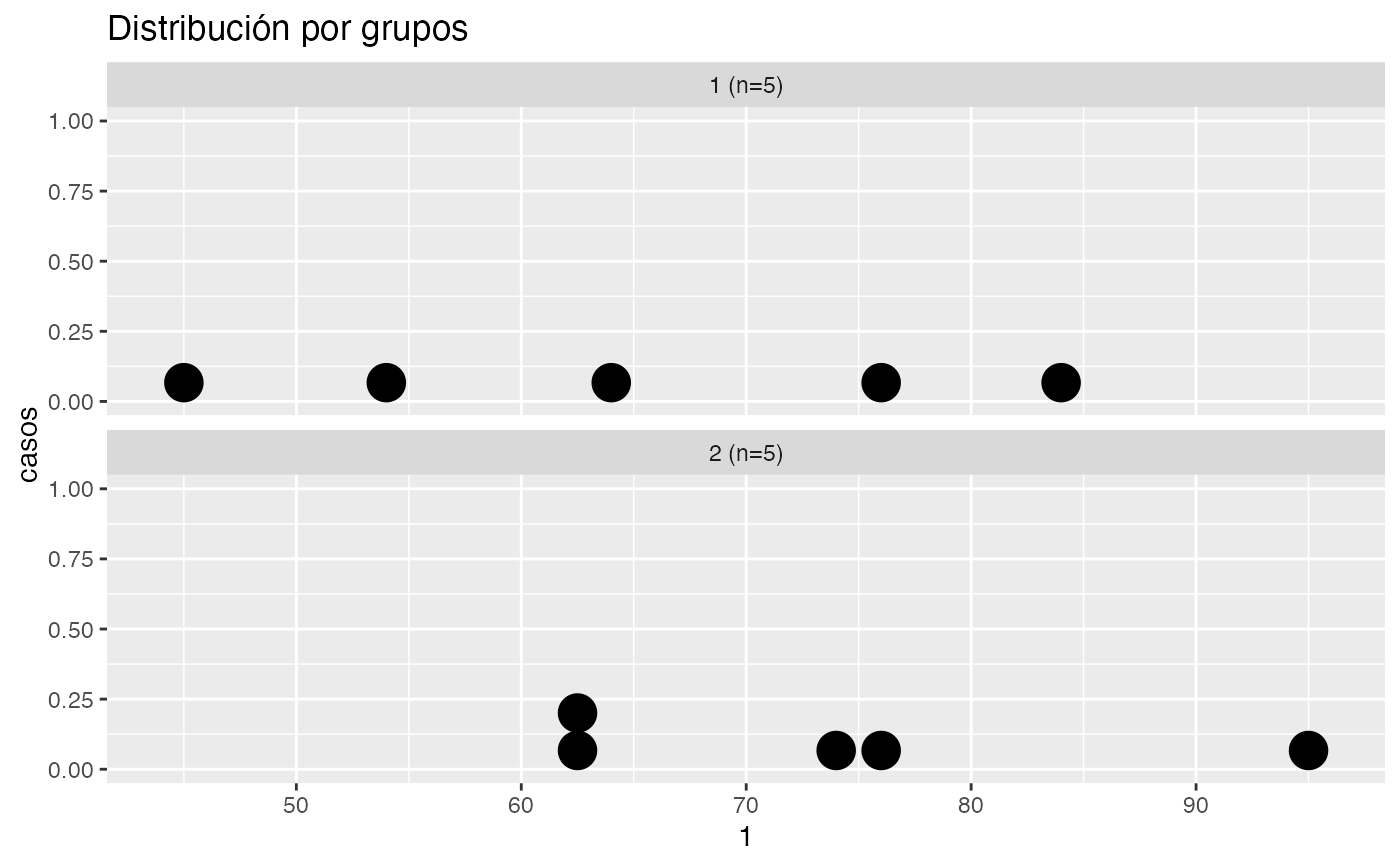
testt(m=peso, grupos=sexo)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: 1, 2
#>
#> n media dt sem IC
#> peso [1] 5 59.6 10.831 4.844 (46.152, 73.048)
#> peso [2] 5 79.0 11.446 5.119 (64.789, 93.211)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = 1, W = 0.980, gl = 5, p = 0.936
#> [2] Para grupo = 2, W = 0.969, gl = 5, p = 0.869
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.117, gl₁ = 4, gl₂ = 4, p = 0.917
#>
#> # Diferencia de medias (peso [2] - peso [1])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 2.753, gl = 8
#> p = 0.025 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.012 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.150, 35.650)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 2.753, gl = 7.98
#> p = 0.025 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.013 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.141, 35.659)
# [A.2] Con informacion muestral sintetizada
testt(m=37, s=5, n=158, m0=25)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 158.000
#> media = 37.000
#> d.t. = 5.000
#> sem = 0.398
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (36.214, 37.786)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=25.000
#> texp = 30.168, gl = 157
#> p < 0.001 para la alternativa bilateral H₁:μ≠μ₀
#> p < 0.001 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (11.214, 12.786)
testt(m=37, s=7, n=158, m0=36,delta=3,potencia=0.95)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 158.000
#> media = 37.000
#> d.t. = 7.000
#> sem = 0.557
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (35.900, 38.100)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=36.000
#> texp = 1.796, gl = 157
#> p = 0.074 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.037 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ-μ₀) = (-0.100, 2.100)
#>
#> # Estudio de la potencia: δ = 3 -> [33, 39], potencia θ = 95%
#> 90%-IC(μ-μ₀) = (0.079, 1.921) con μ₀ = 36.000
#> 90%-IC(μ) = (36.079, 37.921)
#>
#> ---[--|(-)-]---- potencia > 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#> # Estimación del tamaño muestral
#> Efecto a detectar: δ = 3
#> Potencia: θ = 0.95
#> Error de tipo I: α = 0.05
#> n ⩾ 72 casos
#>
# [B] Test con dos muestras independientes
# [B.1] 2 muestras independientes con datos individuales
sexo<-c( 1,2,2,2,1,1,2,2,1,1)
peso<-c(54,64,76,84,45,74,76,95,63,62)
testt(m=peso, grupos=sexo)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: 1, 2
#>
#> n media dt sem IC
#> peso [1] 5 59.6 10.831 4.844 (46.152, 73.048)
#> peso [2] 5 79.0 11.446 5.119 (64.789, 93.211)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = 1, W = 0.980, gl = 5, p = 0.936
#> [2] Para grupo = 2, W = 0.969, gl = 5, p = 0.869
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.117, gl₁ = 4, gl₂ = 4, p = 0.917
#>
#> # Diferencia de medias (peso [2] - peso [1])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 2.753, gl = 8
#> p = 0.025 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.012 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.150, 35.650)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 2.753, gl = 7.98
#> p = 0.025 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.013 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.141, 35.659)
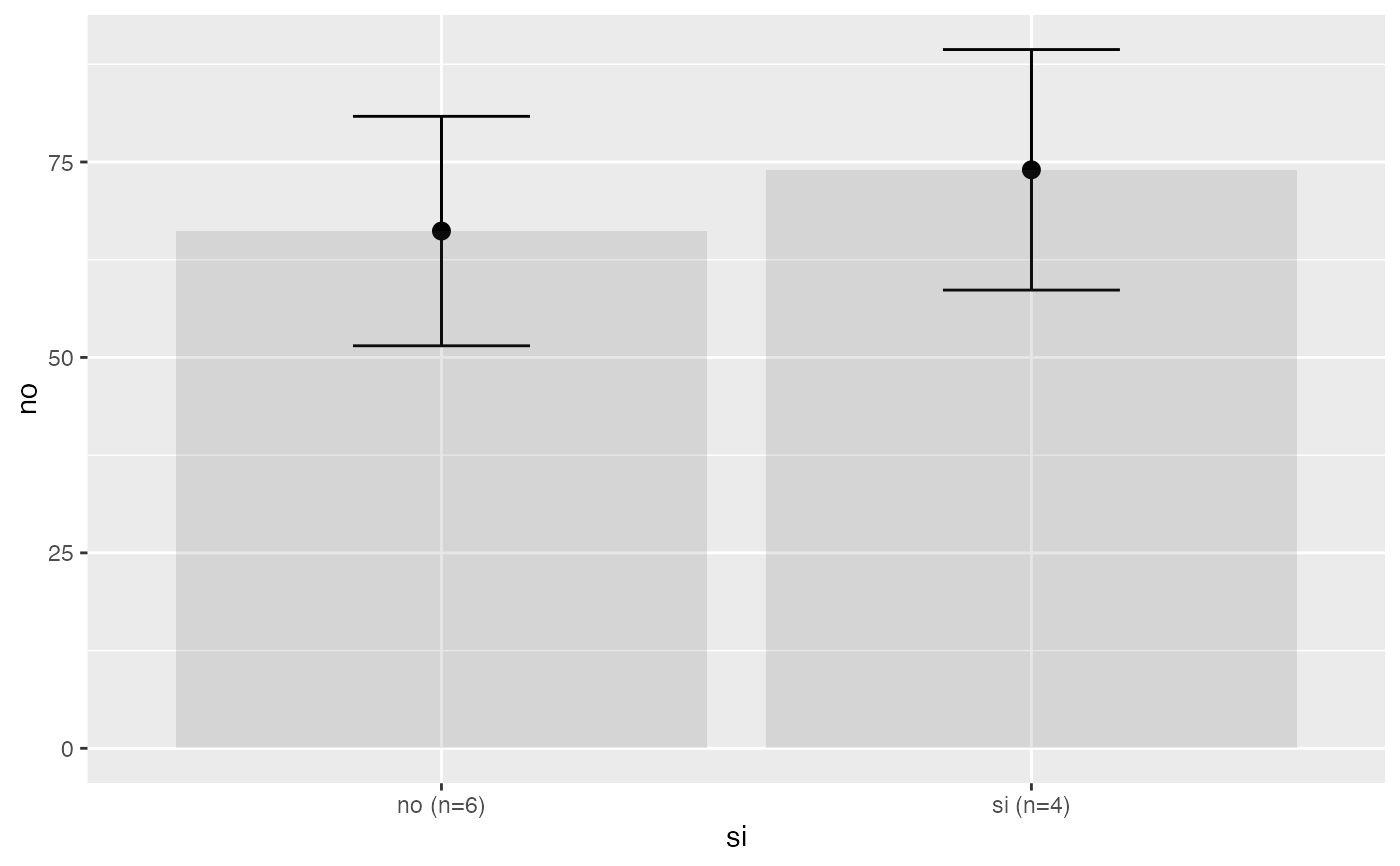
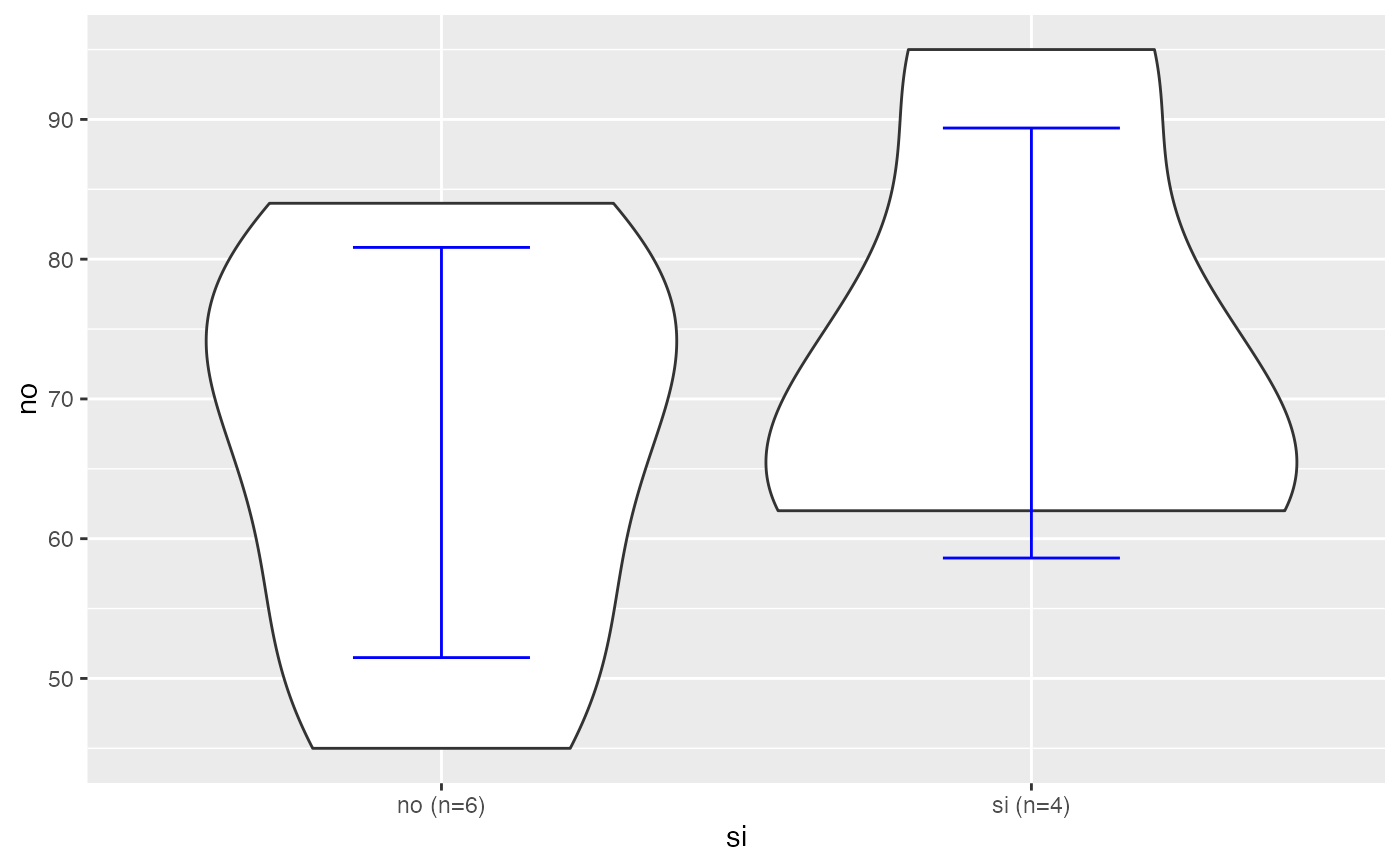
 fuma<-c("si","no","si","no","no","no","no","si","no","si")
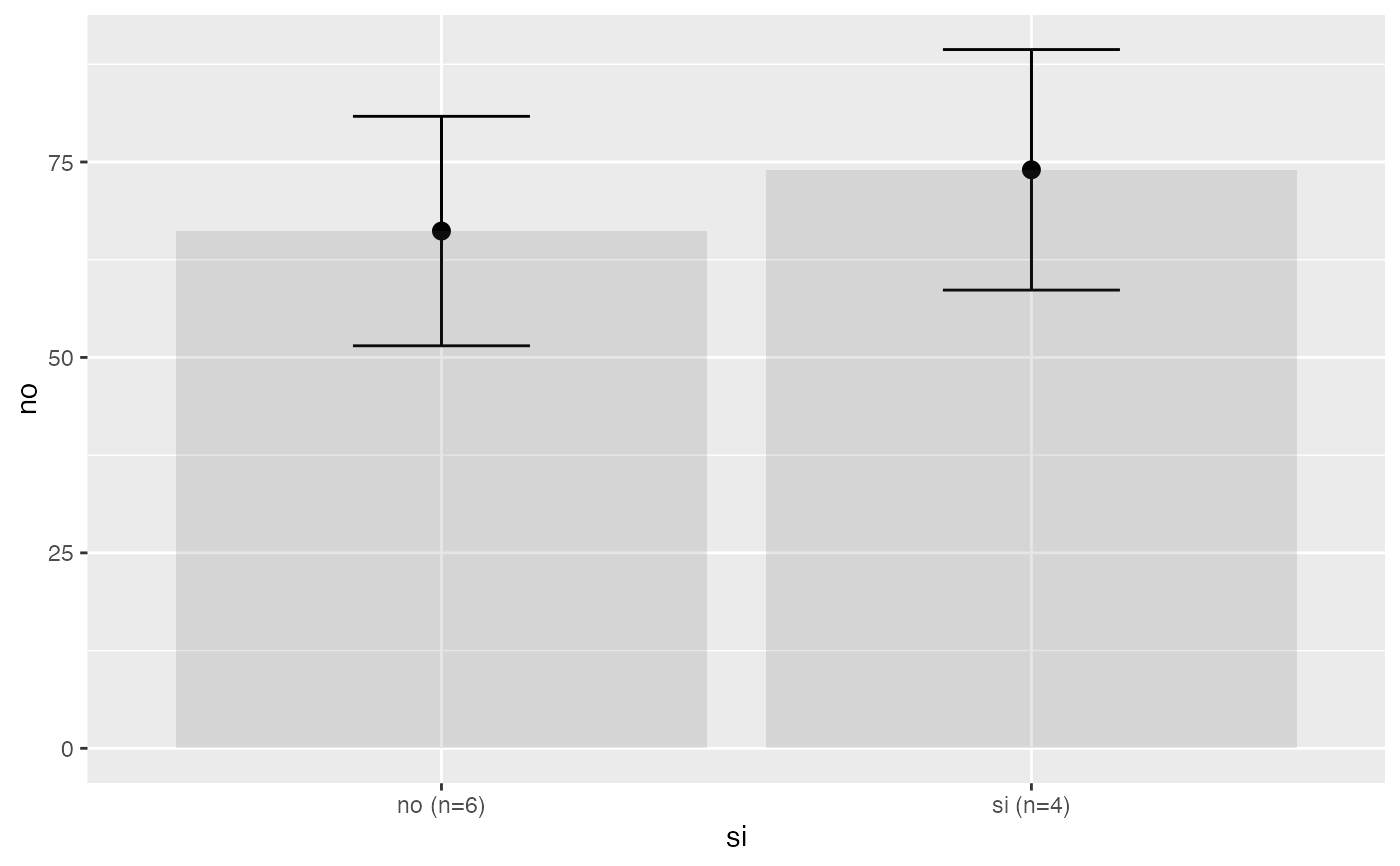
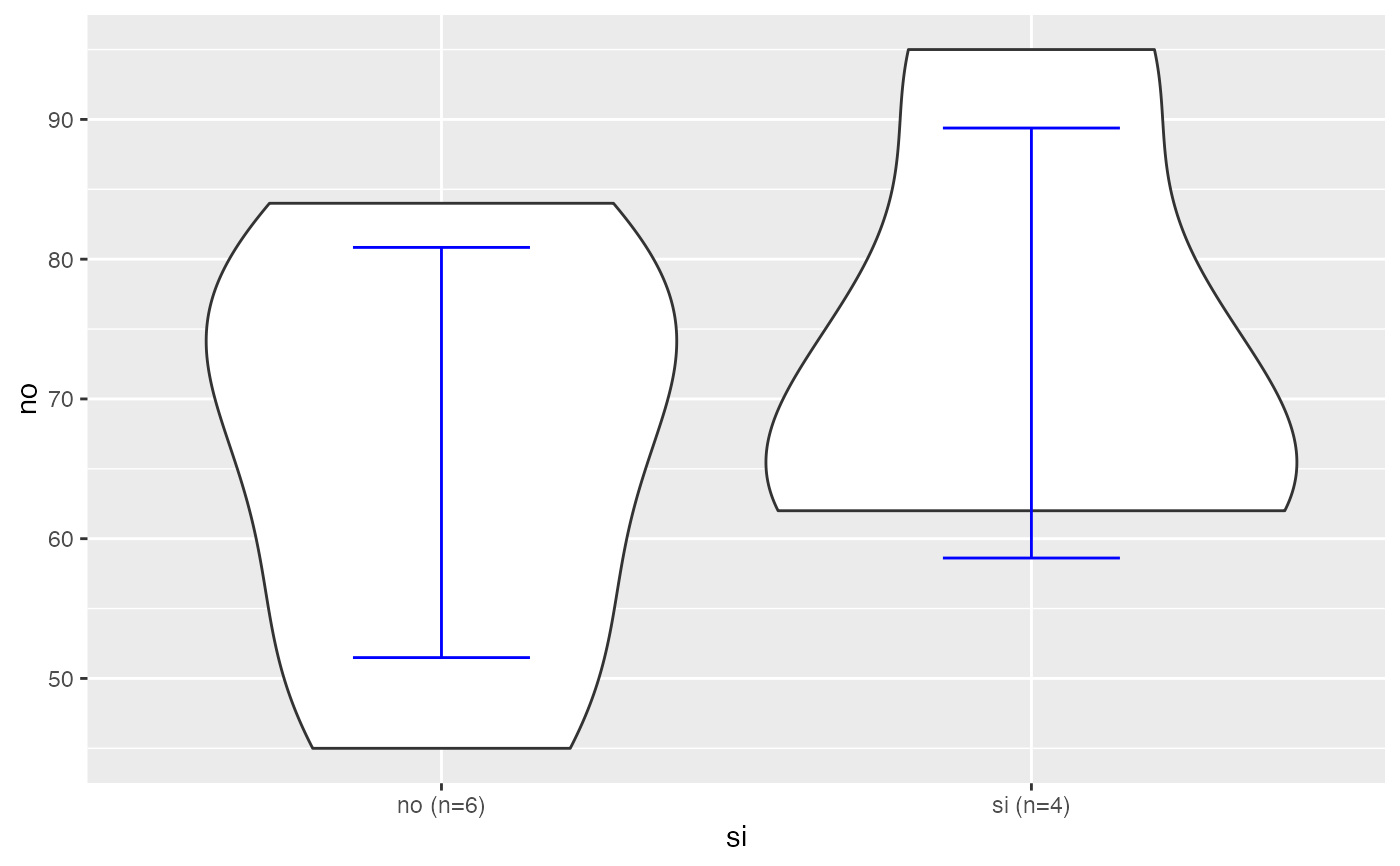
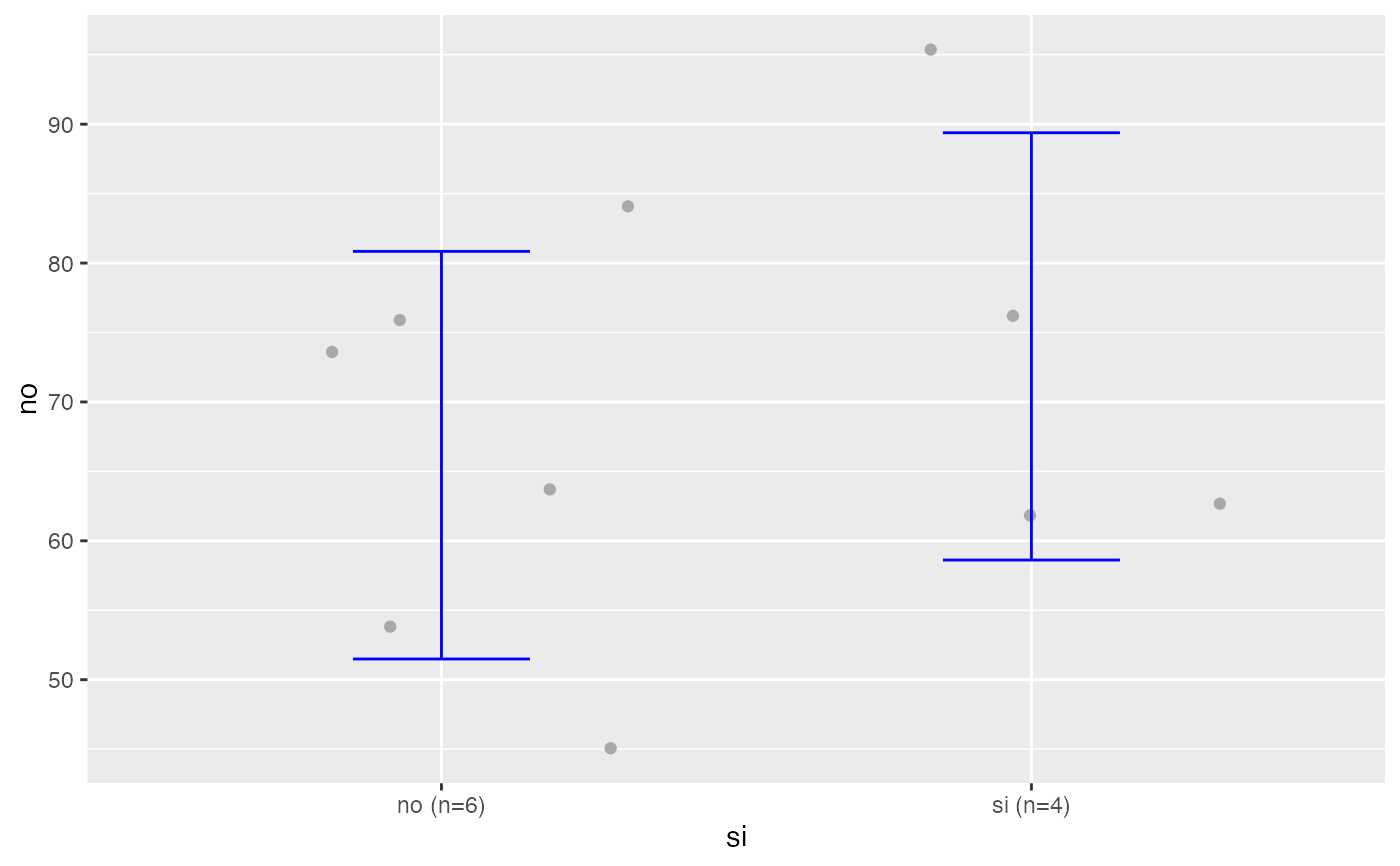
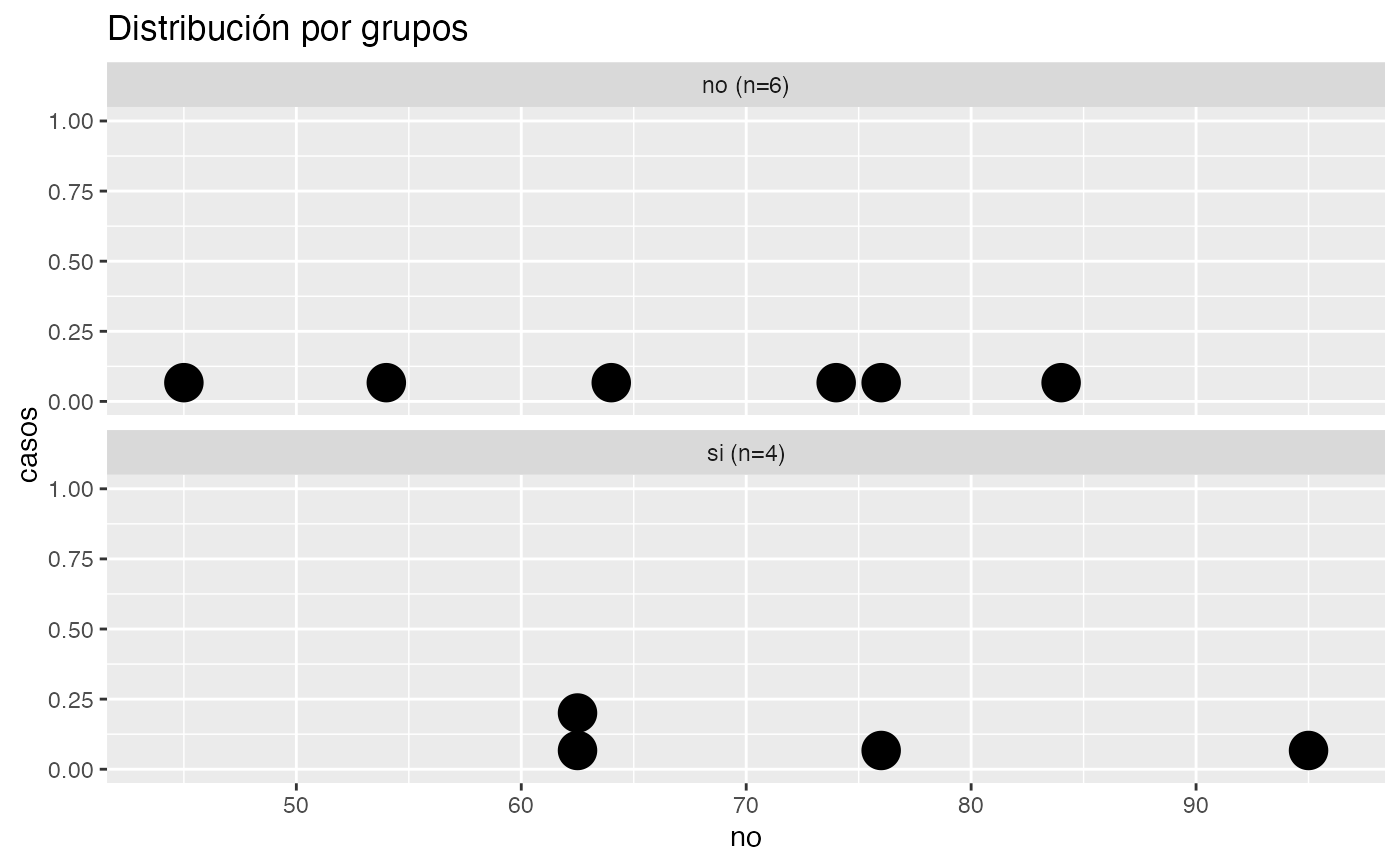
testt(m=peso, grupos=fuma,delta=5,potencia=0.95)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: no, si
#>
#> n media dt sem IC
#> peso [no] 6 67.667 13.604 5.554 (53.39, 81.943)
#> peso [si] 4 71.750 17.970 8.985 (43.156, 100.344)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = no, W = 0.947, gl = 6, p = 0.719
#> [2] Para grupo = si, W = 0.961, gl = 4, p = 0.783
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.745, gl₁ = 3, gl₂ = 5, p = 0.547
#>
#> # Diferencia de medias (peso [si] - peso [no])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 0.411, gl = 8
#> p = 0.692 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.346 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-18.821, 26.987)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 0.387, gl = 5.27
#> p = 0.714 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.357 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-22.658, 30.824)
#>
#> # Estudio de la potencia: δ = 5 -> [-5, 5], potencia θ =95%
#> 90%-IC(μ₂-μ₁) = (-16.964, 25.130)
#>
#> -(-[---|---]-)-- potencia < 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=5 con potencia θ=95%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 329 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.321, (gl'=6.89)
#> n₁ ⩾ 314 casos en el grupo [1]
#> n₂ ⩾ 415 casos en el grupo [2]
#>
fuma<-c("si","no","si","no","no","no","no","si","no","si")
testt(m=peso, grupos=fuma,delta=5,potencia=0.95)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: no, si
#>
#> n media dt sem IC
#> peso [no] 6 67.667 13.604 5.554 (53.39, 81.943)
#> peso [si] 4 71.750 17.970 8.985 (43.156, 100.344)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = no, W = 0.947, gl = 6, p = 0.719
#> [2] Para grupo = si, W = 0.961, gl = 4, p = 0.783
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.745, gl₁ = 3, gl₂ = 5, p = 0.547
#>
#> # Diferencia de medias (peso [si] - peso [no])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 0.411, gl = 8
#> p = 0.692 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.346 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-18.821, 26.987)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 0.387, gl = 5.27
#> p = 0.714 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.357 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-22.658, 30.824)
#>
#> # Estudio de la potencia: δ = 5 -> [-5, 5], potencia θ =95%
#> 90%-IC(μ₂-μ₁) = (-16.964, 25.130)
#>
#> -(-[---|---]-)-- potencia < 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=5 con potencia θ=95%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 329 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.321, (gl'=6.89)
#> n₁ ⩾ 314 casos en el grupo [1]
#> n₂ ⩾ 415 casos en el grupo [2]
#>
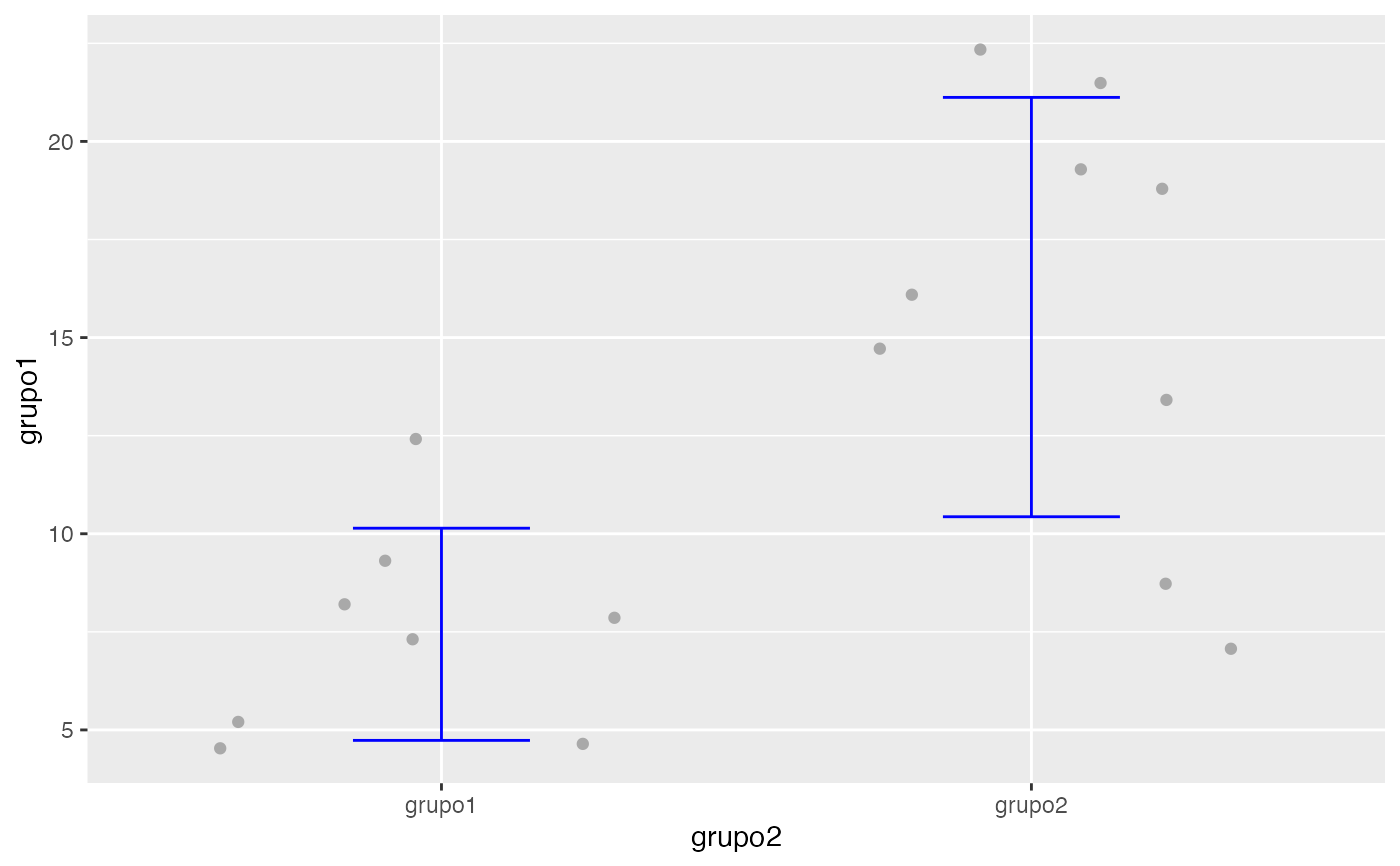
 grupo1<-c(12.5,7.4,8.3,4.6,5.1,7.8,9.2,4.6)
grupo2<-c(8.7,14.8,13.5,16.1,7.1,19.2,21.5,22.4,18.7)
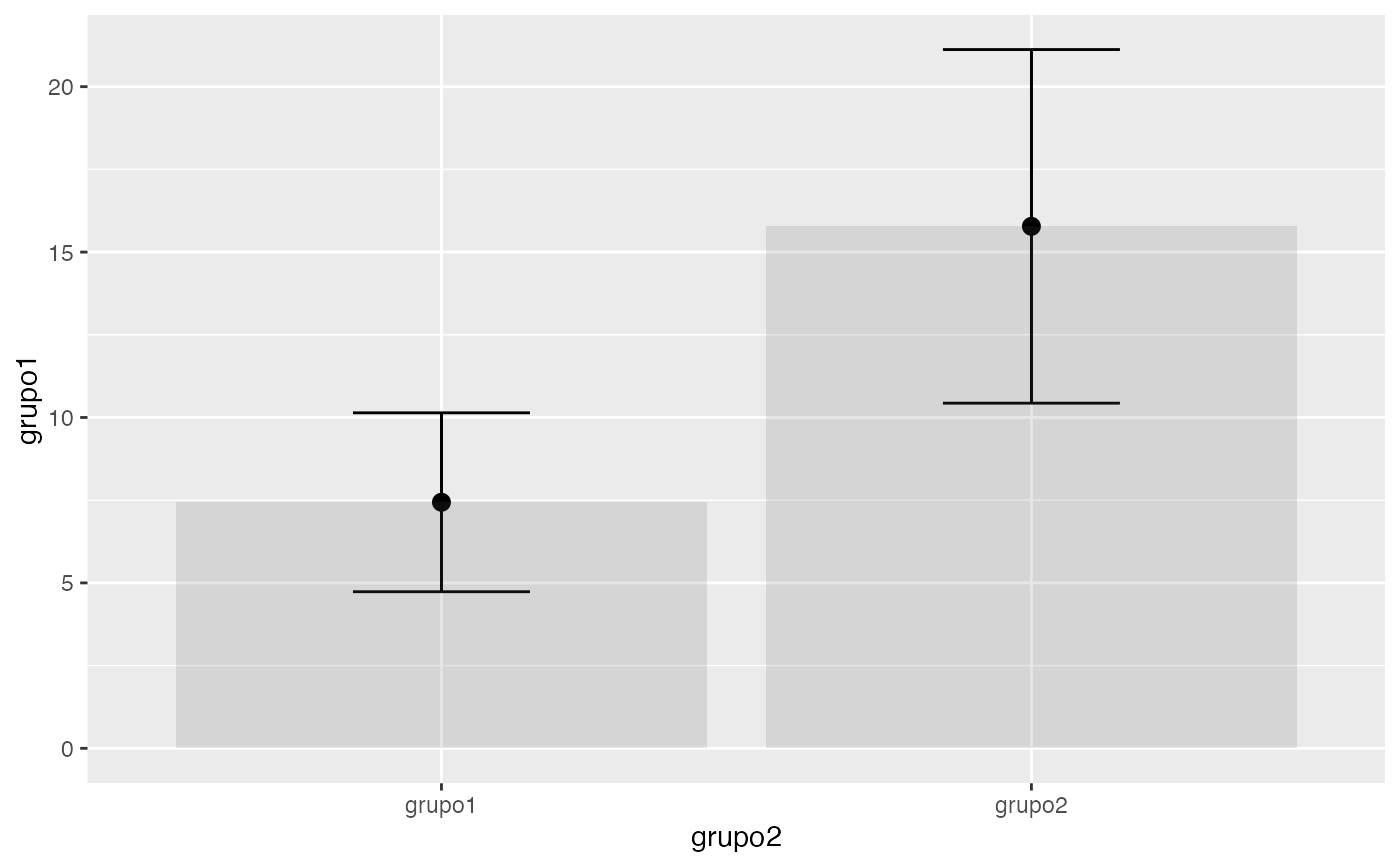
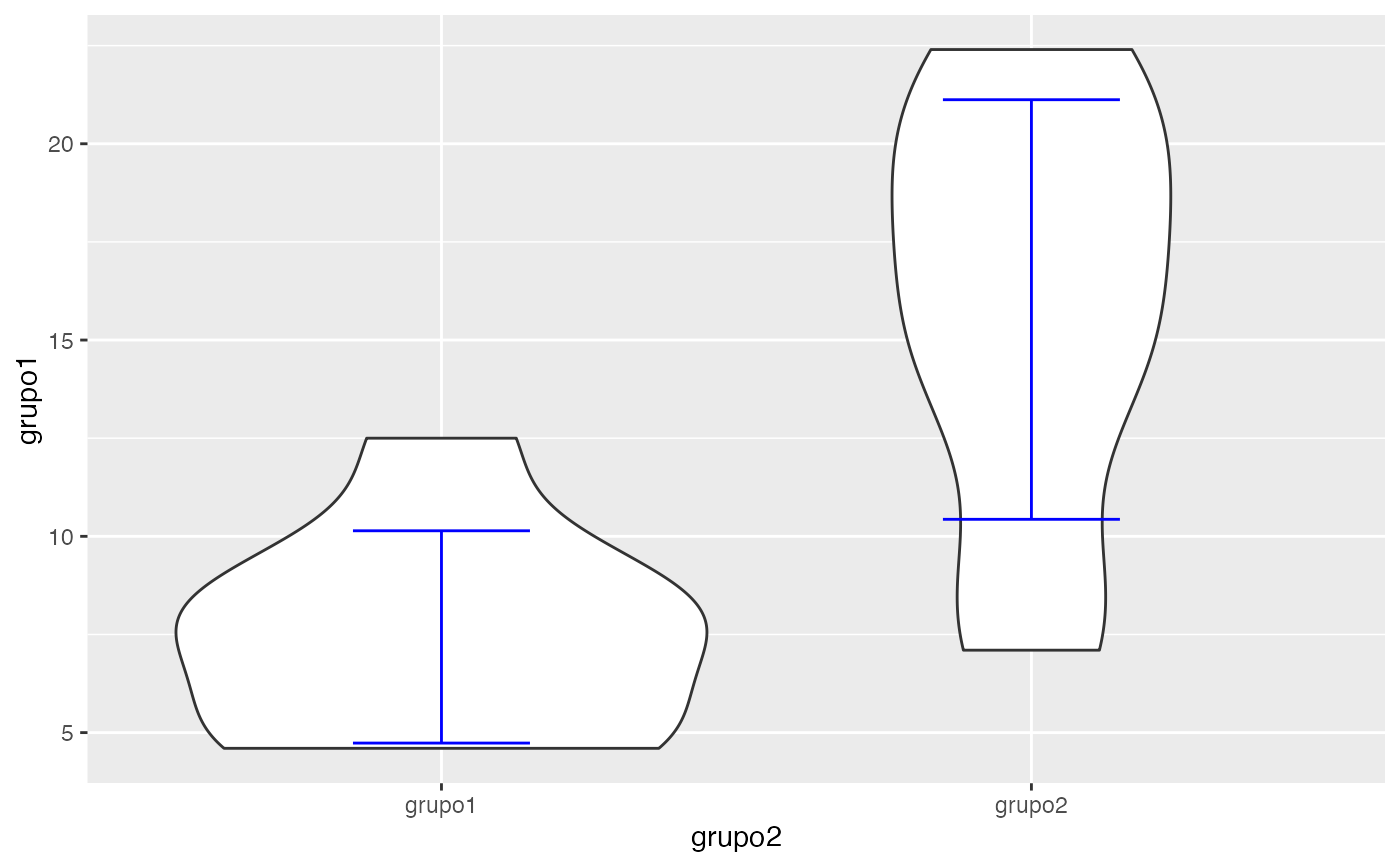
testt(m1=grupo1, m2=grupo2)
#>
#> [!] Las muestras grupo1 y grupo2 tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: grupo1, grupo2
#>
#> n media dt sem IC
#> grupo1 8 7.438 2.704 0.956 (5.177, 9.698)
#> grupo2 9 15.778 5.344 1.781 (11.67, 19.886)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = grupo1, W = 0.908, gl = 8, p = 0.342
#> [2] Para grupo = grupo2, W = 0.940, gl = 9, p = 0.585
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.907, gl₁ = 8, gl₂ = 7, p = 0.089
#>
#> # Diferencia de medias (grupo2 - grupo1)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 3.975, gl = 15
#> p = 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.868, 12.812)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 4.125, gl = 12.12
#> p = 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.940, 12.740)
grupo1<-c(12.5,7.4,8.3,4.6,5.1,7.8,9.2,4.6)
grupo2<-c(8.7,14.8,13.5,16.1,7.1,19.2,21.5,22.4,18.7)
testt(m1=grupo1, m2=grupo2)
#>
#> [!] Las muestras grupo1 y grupo2 tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: grupo1, grupo2
#>
#> n media dt sem IC
#> grupo1 8 7.438 2.704 0.956 (5.177, 9.698)
#> grupo2 9 15.778 5.344 1.781 (11.67, 19.886)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = grupo1, W = 0.908, gl = 8, p = 0.342
#> [2] Para grupo = grupo2, W = 0.940, gl = 9, p = 0.585
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.907, gl₁ = 8, gl₂ = 7, p = 0.089
#>
#> # Diferencia de medias (grupo2 - grupo1)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 3.975, gl = 15
#> p = 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.868, 12.812)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 4.125, gl = 12.12
#> p = 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (3.940, 12.740)
 # [B.2] 2 muestras independientes con datos sintetizados
testt(n1=123, m1=25, s1=6, n2=87, m2=20, s2=8)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: 1, 2
#>
#> n media dt sem IC
#> Muestra 1 123 25 6.000 0.541 (23.929, 26.071)
#> Muestra 2 87 20 8.000 0.858 (18.295, 21.705)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.778, gl₁ = 86, gl₂ = 122, p = 0.003
#>
#> # Diferencia de medias (Muestra 1 - Muestra 2)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₁-μ₂=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 5.175, gl = 208
#> p < 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁>μ₂
#> 95%-IC(μ₁-μ₂) = (3.095, 6.905)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 4.931, gl = 151.18
#> p < 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁>μ₂
#> 95%-IC(μ₁-μ₂) = (2.996, 7.004)
#> Error in grpsggp(x = c(m1_m, m2_m), f = as.factor(c("1", "2")), se = c(m1_s, m2_s), ggid = c(9), lbls = c("Media(sd)", "Muestra")): vectores de m() 2 y se() 4 de diferente dimensión
# [C] Test con dos muestras relacionadas
# [C.1] 2 muestras apareadas con datos individuales
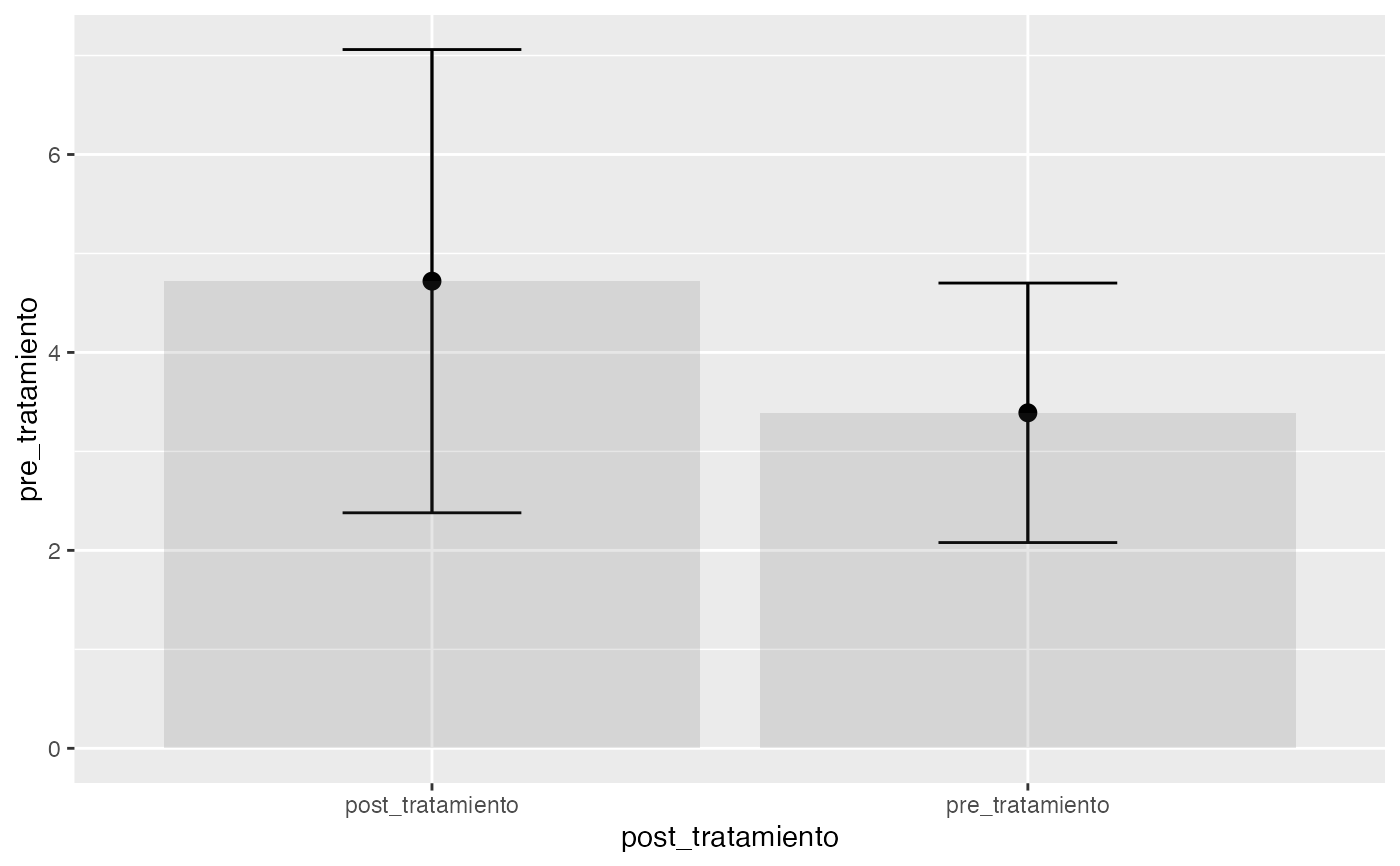
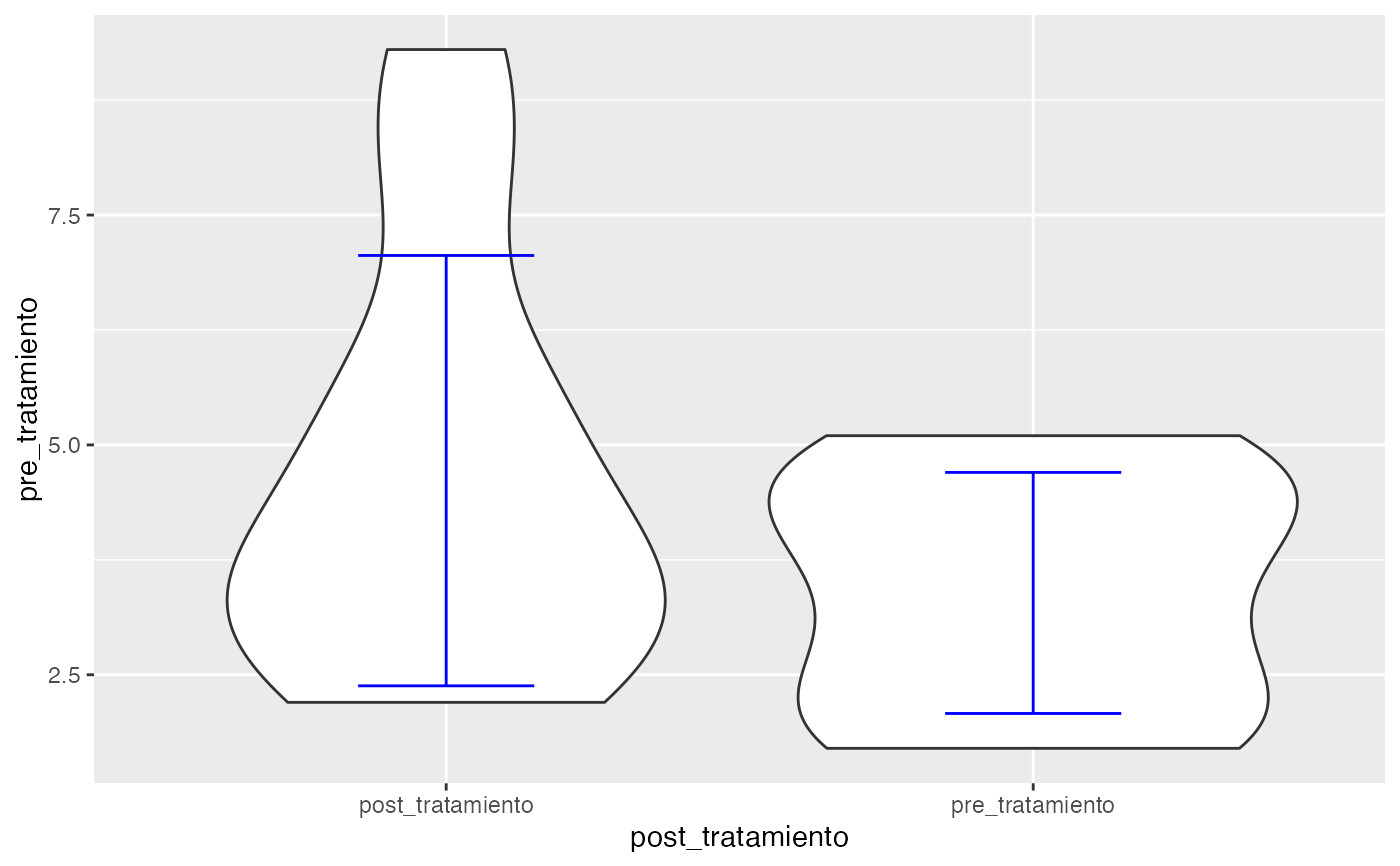
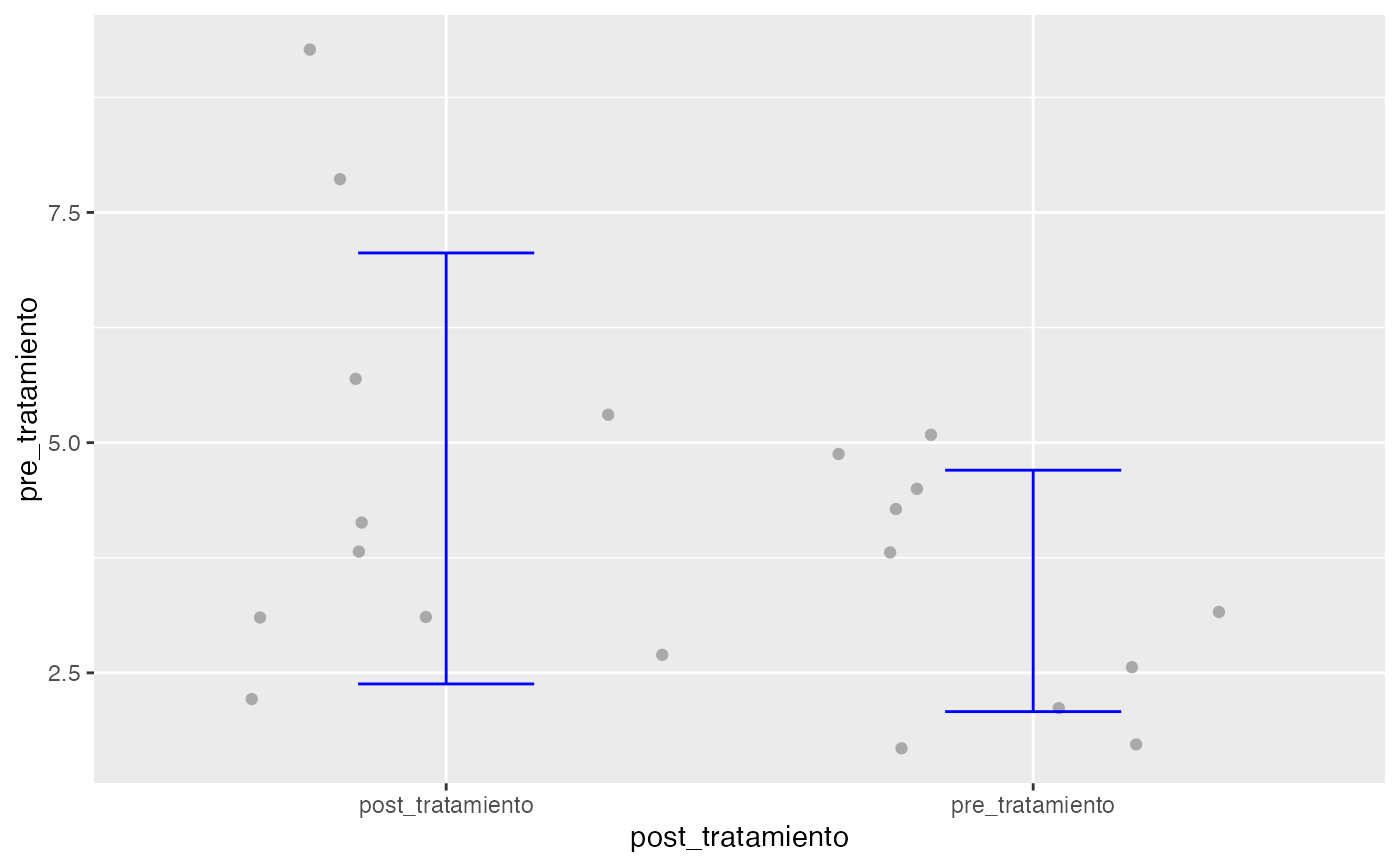
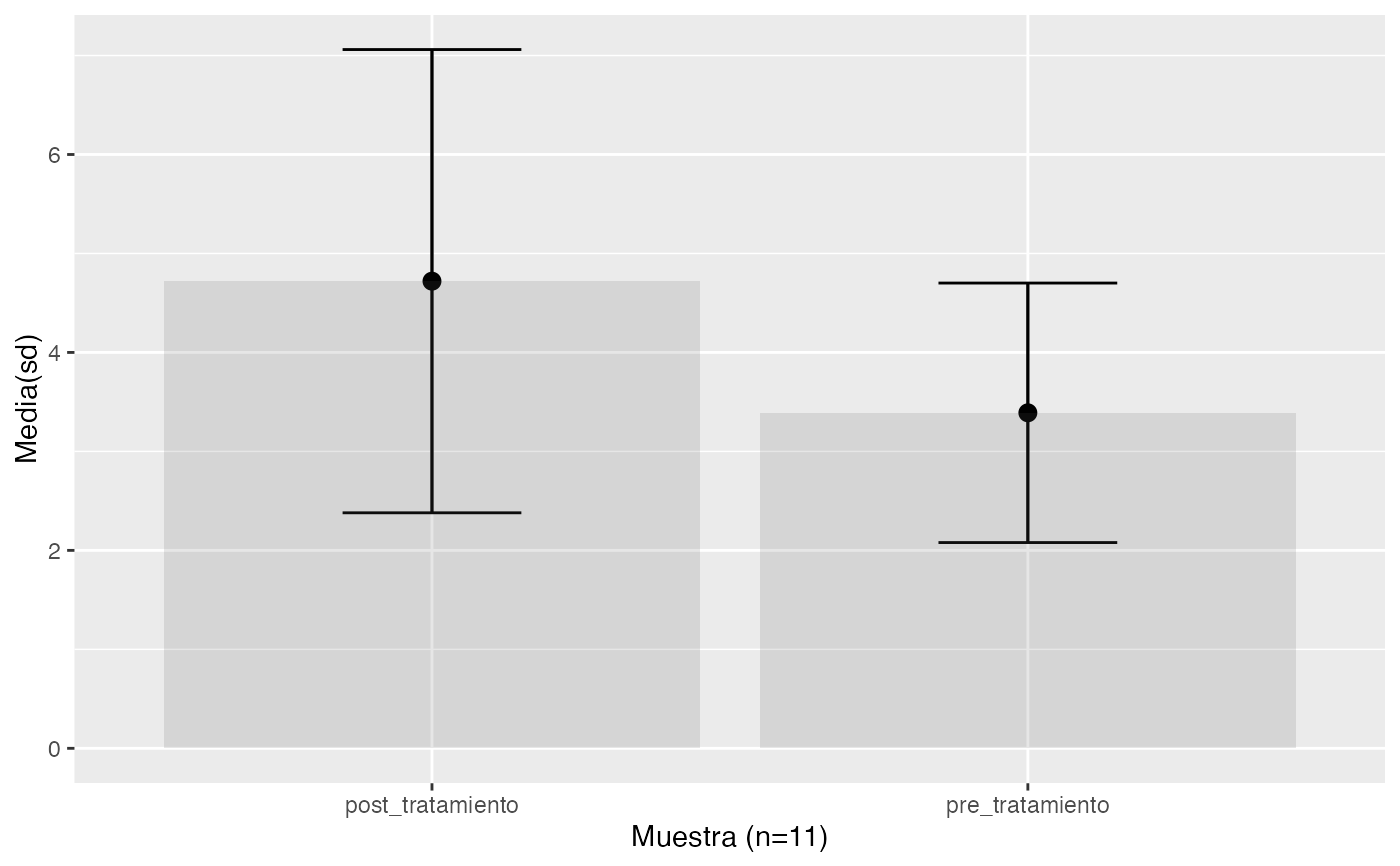
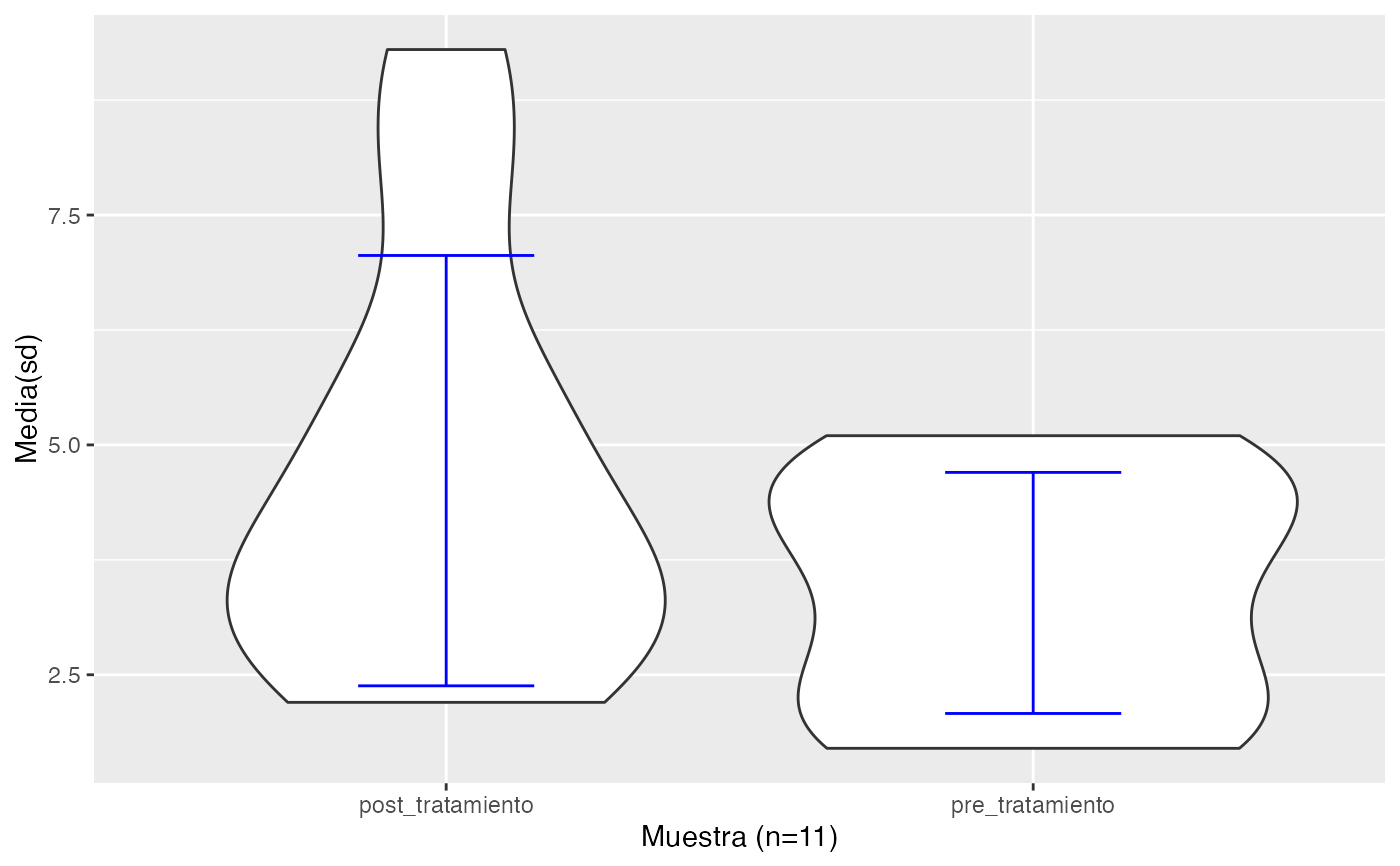
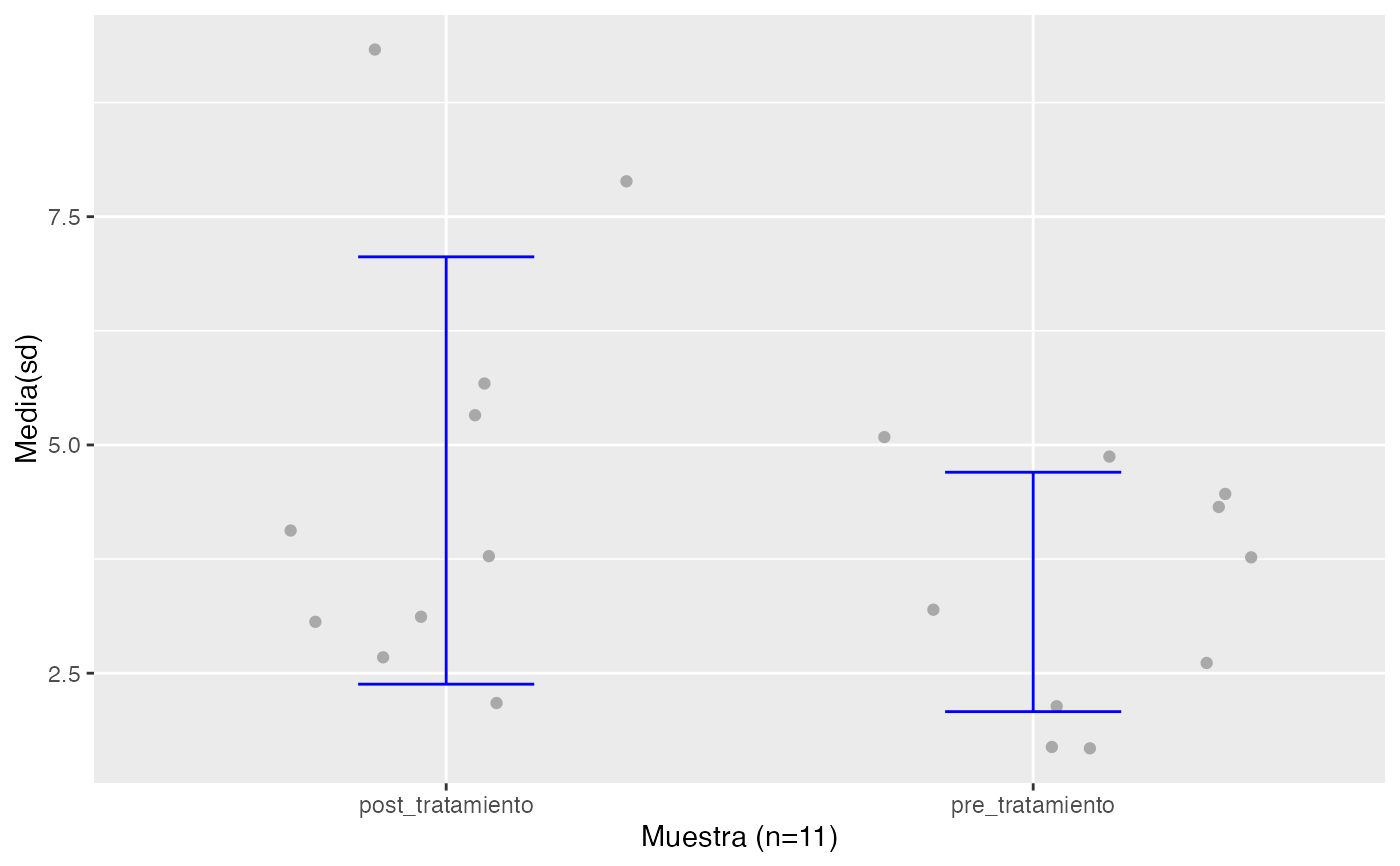
pre_tratamiento<-c(3.2,4.5,1.7,2.6,1.7,4.3,2.1,3.8,4.9,5.1,NA)
post_tratamiento<-c(3.8,4.1,2.2,3.1,2.7,9.3,7.9,3.1,5.7,5.3,NA)
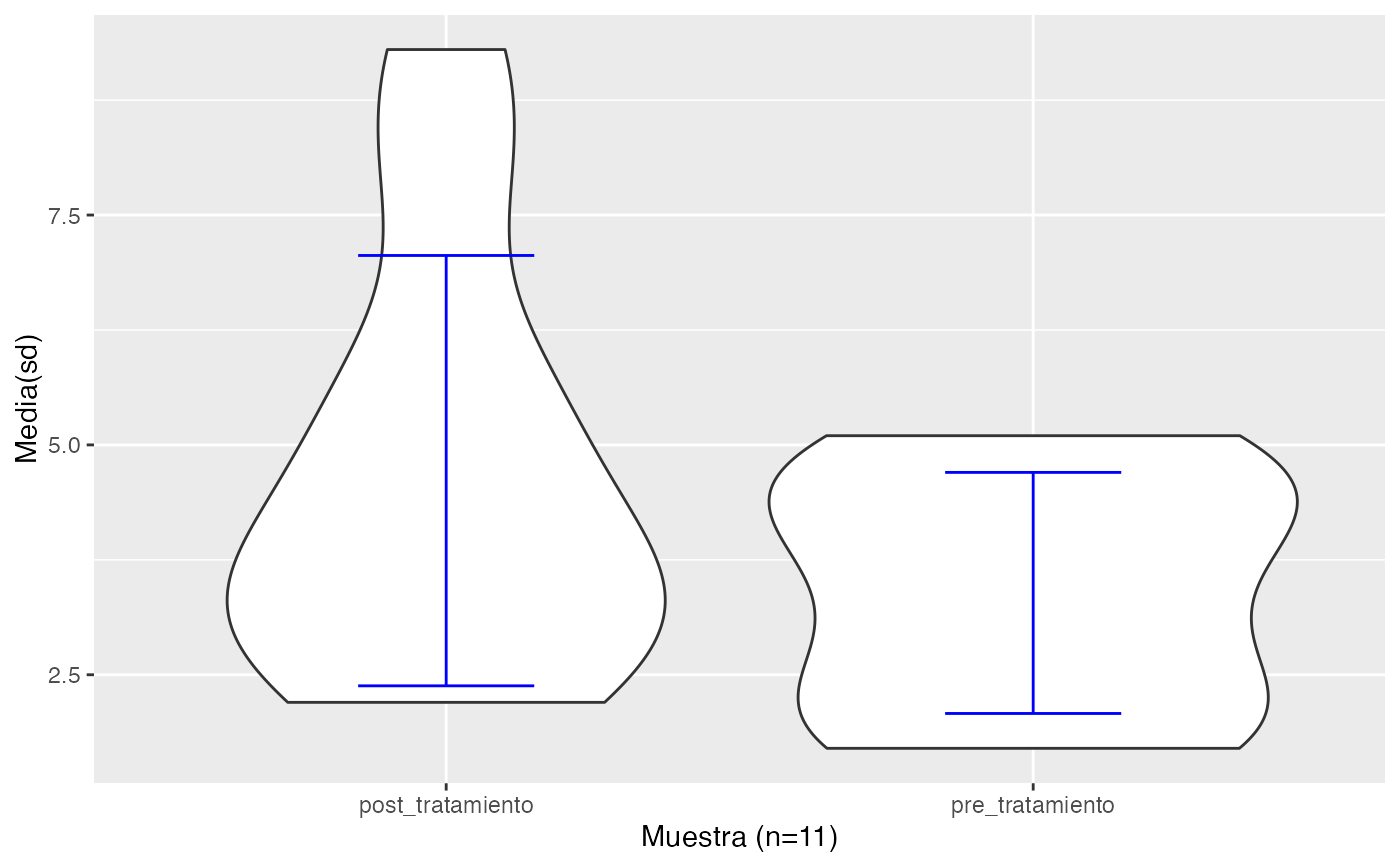
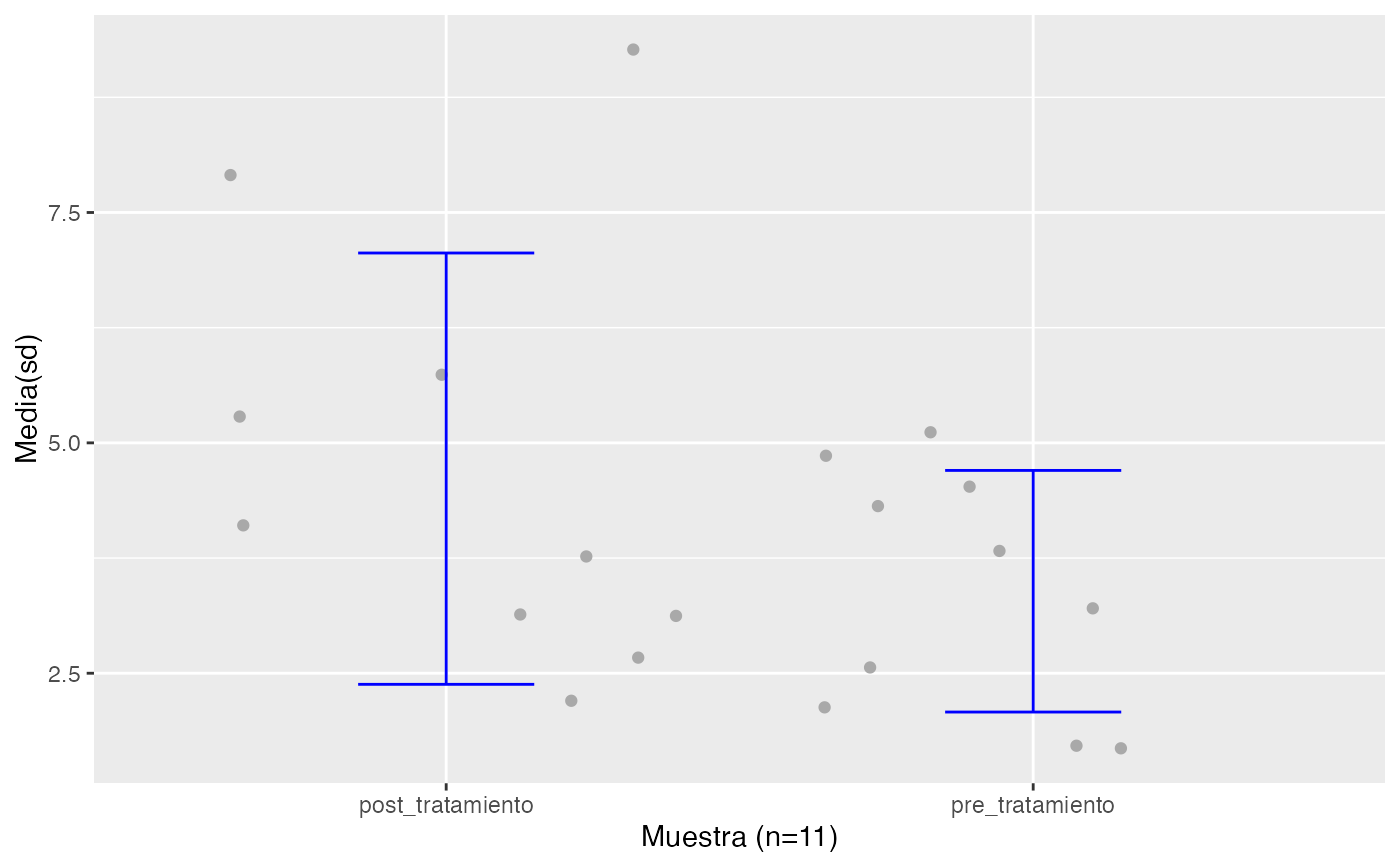
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> Diferencia 10 0 1.33 2.215 0.700 (-0.254, 2.914)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁=μ₂ (test de homogeneidad)
#> texp = 1.899, gl = 9
#> p = 0.090 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.045 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.254, 2.914)
# [B.2] 2 muestras independientes con datos sintetizados
testt(n1=123, m1=25, s1=6, n2=87, m2=20, s2=8)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: 1, 2
#>
#> n media dt sem IC
#> Muestra 1 123 25 6.000 0.541 (23.929, 26.071)
#> Muestra 2 87 20 8.000 0.858 (18.295, 21.705)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.778, gl₁ = 86, gl₂ = 122, p = 0.003
#>
#> # Diferencia de medias (Muestra 1 - Muestra 2)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₁-μ₂=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 5.175, gl = 208
#> p < 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁>μ₂
#> 95%-IC(μ₁-μ₂) = (3.095, 6.905)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 4.931, gl = 151.18
#> p < 0.001 para la alternativa bilateral H₁:μ₁≠μ₂
#> p < 0.001 para la alternativa unilateral H₁:μ₁>μ₂
#> 95%-IC(μ₁-μ₂) = (2.996, 7.004)
#> Error in grpsggp(x = c(m1_m, m2_m), f = as.factor(c("1", "2")), se = c(m1_s, m2_s), ggid = c(9), lbls = c("Media(sd)", "Muestra")): vectores de m() 2 y se() 4 de diferente dimensión
# [C] Test con dos muestras relacionadas
# [C.1] 2 muestras apareadas con datos individuales
pre_tratamiento<-c(3.2,4.5,1.7,2.6,1.7,4.3,2.1,3.8,4.9,5.1,NA)
post_tratamiento<-c(3.8,4.1,2.2,3.1,2.7,9.3,7.9,3.1,5.7,5.3,NA)
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> Diferencia 10 0 1.33 2.215 0.700 (-0.254, 2.914)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁=μ₂ (test de homogeneidad)
#> texp = 1.899, gl = 9
#> p = 0.090 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.045 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.254, 2.914)
 #>
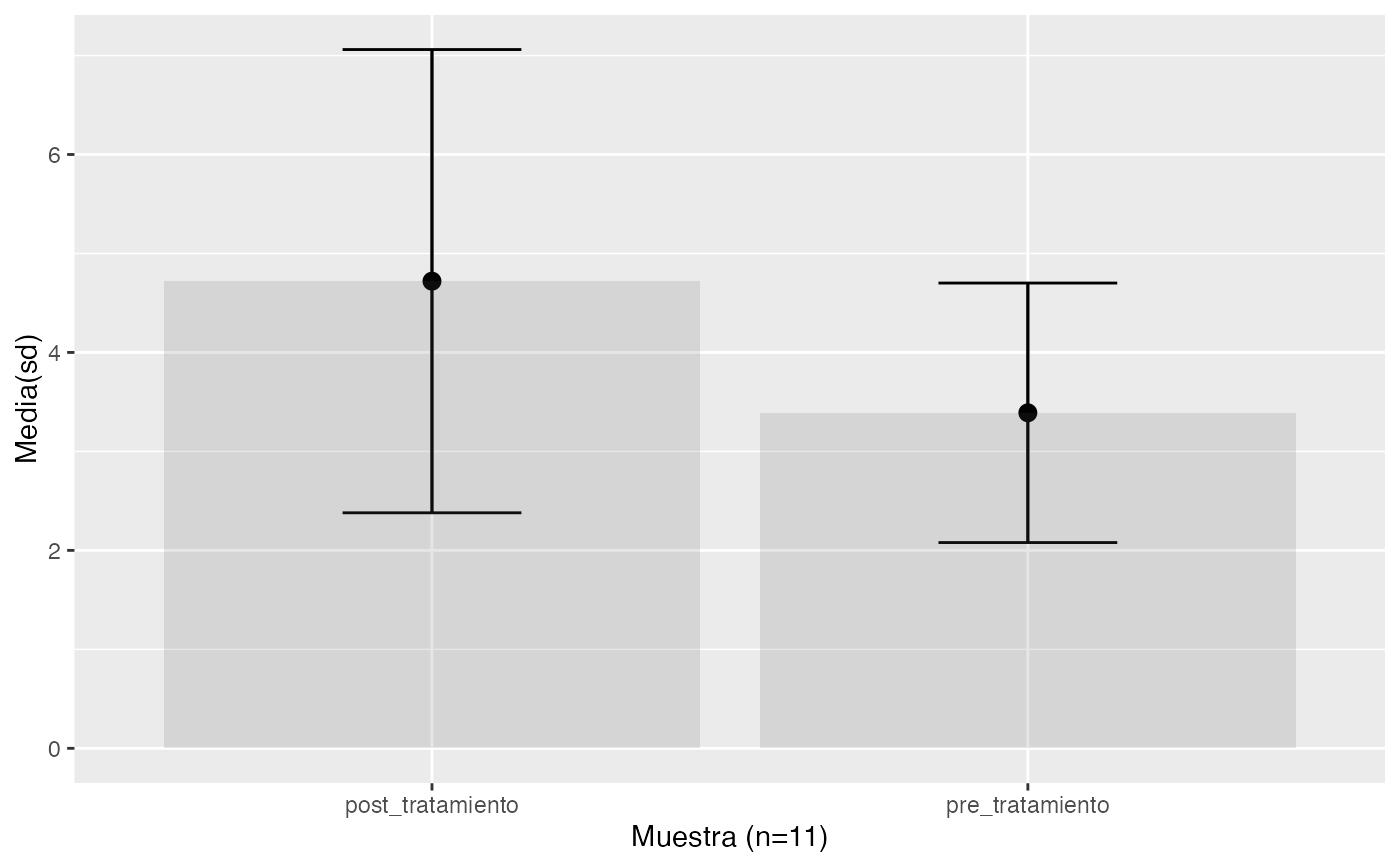
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE, delta=2,m0=0.1)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> Diferencia 10 0 1.33 2.215 0.700 (-0.254, 2.914)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁-μ₂=μ₀ con μ₀=0.1
#> texp = 1.756, gl = 9
#> p = 0.113 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.056 para la alternativa unilateral H₁:μ>μ₀
#> 95%-IC(μ-μ₀) = (-0.354, 2.814)
#> con μ=μ₂-μ₁ y μ₀=0.1
#>
#>
#> # Estudio de la potencia: δ = 2 -> [-1.9, 2.1], potencia θ= 80%
#> 60%-IC((μ₂-μ₁)-0.1) = (0.611, 1.849)
#>
#> ---[--|(-)-]---- potencia > 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#>
#> # Estimación del tamaño muestral:
#> Diferencia a detectar: δ =2
#> Error de tipo I: α= 0.050
#> Potencia: θ = 0.800
#> n ⩾ 13 casos
#>
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE, delta=2,m0=0.1)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> Diferencia 10 0 1.33 2.215 0.700 (-0.254, 2.914)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁-μ₂=μ₀ con μ₀=0.1
#> texp = 1.756, gl = 9
#> p = 0.113 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.056 para la alternativa unilateral H₁:μ>μ₀
#> 95%-IC(μ-μ₀) = (-0.354, 2.814)
#> con μ=μ₂-μ₁ y μ₀=0.1
#>
#>
#> # Estudio de la potencia: δ = 2 -> [-1.9, 2.1], potencia θ= 80%
#> 60%-IC((μ₂-μ₁)-0.1) = (0.611, 1.849)
#>
#> ---[--|(-)-]---- potencia > 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#>
#> # Estimación del tamaño muestral:
#> Diferencia a detectar: δ =2
#> Error de tipo I: α= 0.050
#> Potencia: θ = 0.800
#> n ⩾ 13 casos
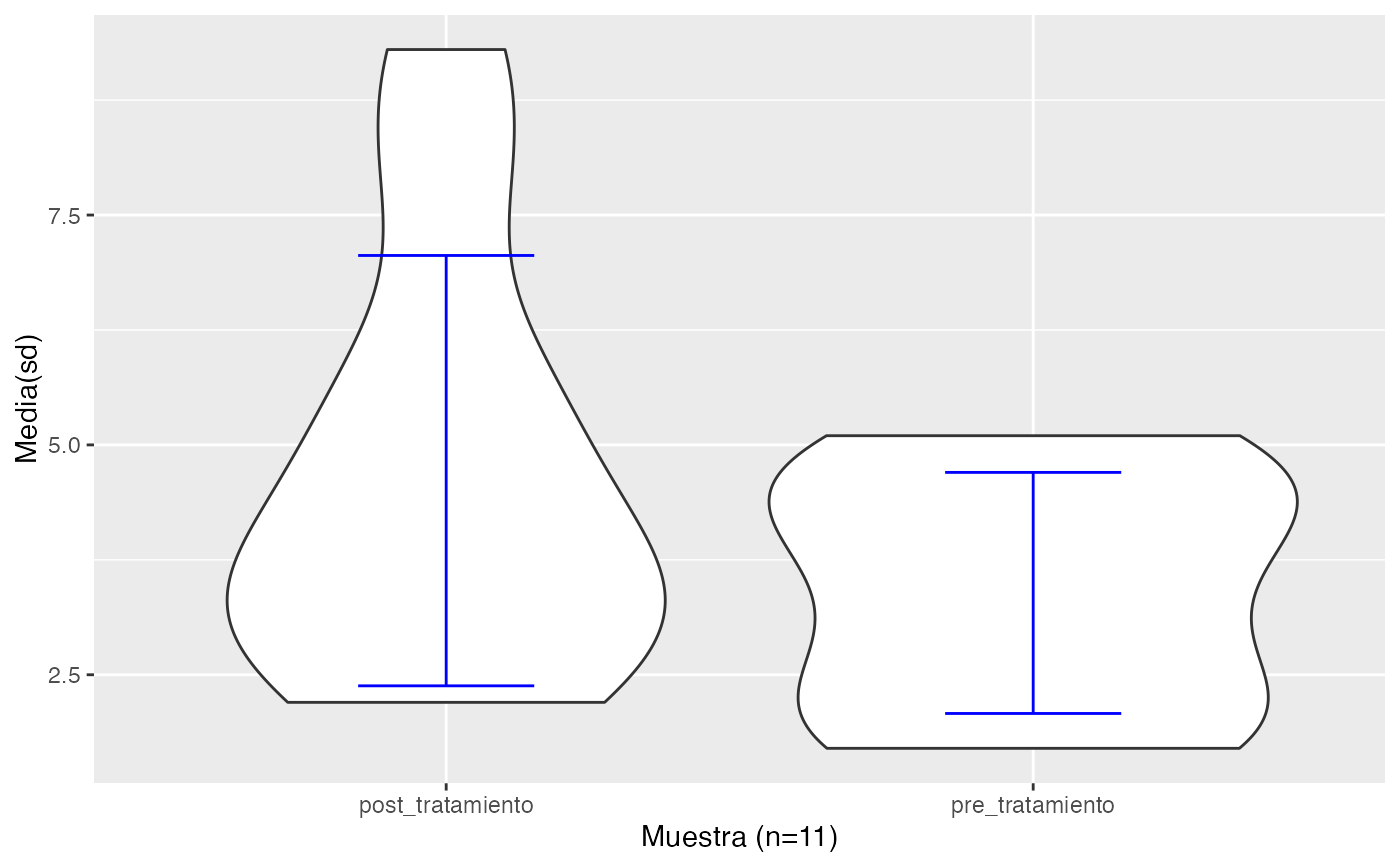
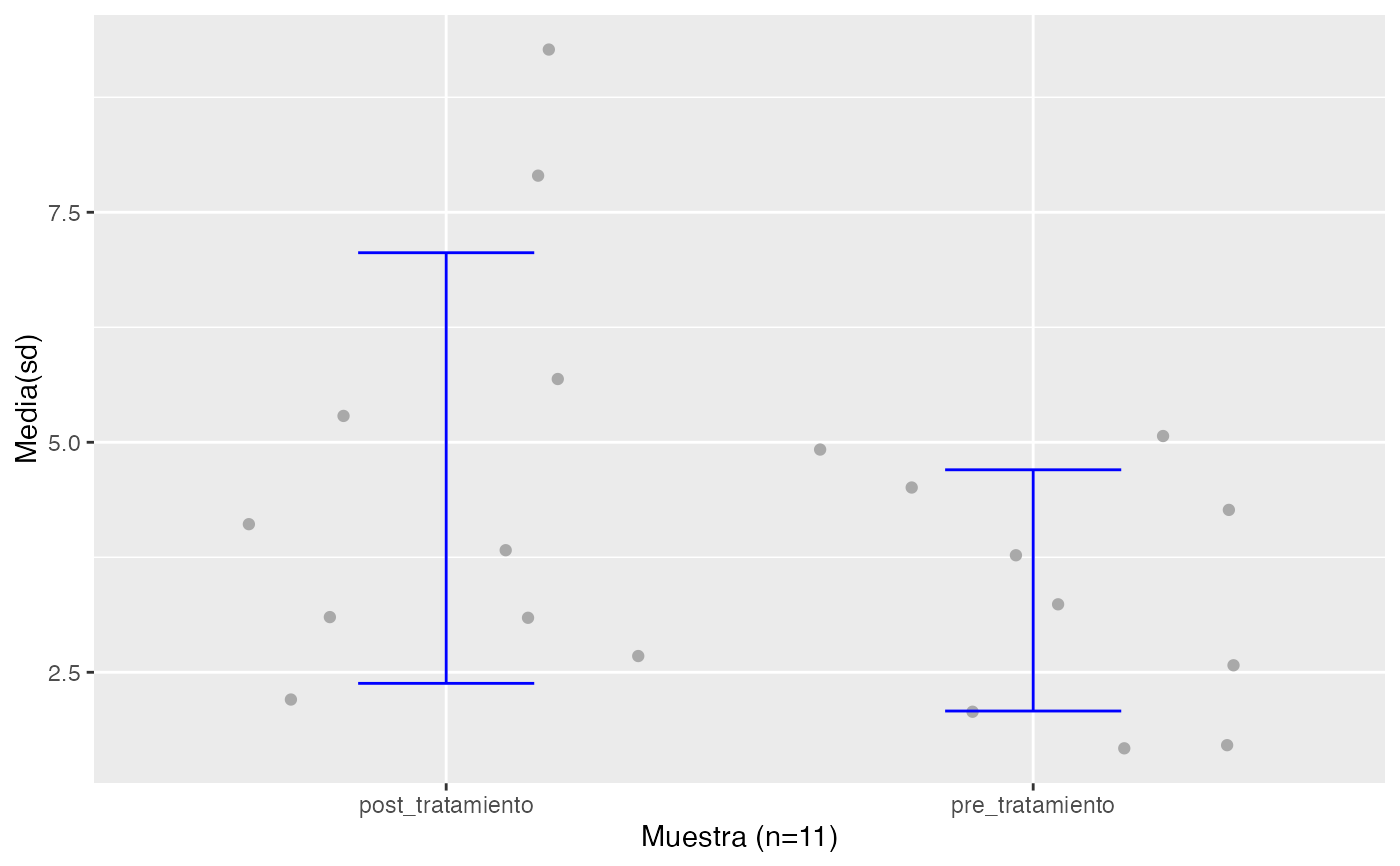 #>
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE, delta=2,m0=0.1, vac=FALSE)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Se aplica una corrección por continuidad (cpc) sobre los IC y el t-test
#> Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem cpc IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 0.05 (2.402, 4.378)
#> post_tratamiento 10 1 4.72 2.340 0.740 0.05 (2.996, 6.444)
#> Diferencia 10 0 1.33 2.215 0.700 0.05 (-0.304, 2.964)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁-μ₂=μ₀ con μ₀=0.1
#> cpc = 0.050
#> texp = 1.685, gl = 9
#> p = 0.126 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.063 para la alternativa unilateral H₁:μ>μ₀
#> 95%-IC(μ-μ₀) = (-0.404, 2.764)
#> con μ=μ₂-μ₁ y μ₀=0.1
#>
#>
#> # Estudio de la potencia: δ = 2 -> [-1.9, 2.1], potencia θ= 80%
#> 60%-IC((μ₂-μ₁)-0.1) = (0.561, 1.799)
#>
#> ---[--|(-)-]---- potencia > 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#>
#> # Estimación del tamaño muestral:
#> Diferencia a detectar: δ =2
#> Error de tipo I: α= 0.050
#> Potencia: θ = 0.800
#> n ⩾ 13 casos
#>
testt(m1=pre_tratamiento, m2=post_tratamiento, par=TRUE, delta=2,m0=0.1, vac=FALSE)
#>
#>
#> # t-test para dos muestras relacionadas
#> # -------------------------------------
#>
#> [!] Se aplica una corrección por continuidad (cpc) sobre los IC y el t-test
#> Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#> Se omiten las parejas con algún dato faltante
#>
#>
#> # Información muestral y estimación de las medias
#> n nmiss media dt sem cpc IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 0.05 (2.402, 4.378)
#> post_tratamiento 10 1 4.72 2.340 0.740 0.05 (2.996, 6.444)
#> Diferencia 10 0 1.33 2.215 0.700 0.05 (-0.304, 2.964)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁, μ₂ y μ₂-μ₁ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Correlación de Pearson entre pre_tratamiento y post_tratamiento:
#> r = 0.373
#>
#>
#> # Normalidad de la diferencia (Test de Shapiro-Wilk)
#> W = 0.741, gl = 10, p = 0.003
#>
#>
#> # t-test H₀:μ₁-μ₂=μ₀ con μ₀=0.1
#> cpc = 0.050
#> texp = 1.685, gl = 9
#> p = 0.126 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.063 para la alternativa unilateral H₁:μ>μ₀
#> 95%-IC(μ-μ₀) = (-0.404, 2.764)
#> con μ=μ₂-μ₁ y μ₀=0.1
#>
#>
#> # Estudio de la potencia: δ = 2 -> [-1.9, 2.1], potencia θ= 80%
#> 60%-IC((μ₂-μ₁)-0.1) = (0.561, 1.799)
#>
#> ---[--|(-)-]---- potencia > 80%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ μ₀-δ μ₀ μ₀+δ
#>
#>
#> # Estimación del tamaño muestral:
#> Diferencia a detectar: δ =2
#> Error de tipo I: α= 0.050
#> Potencia: θ = 0.800
#> n ⩾ 13 casos
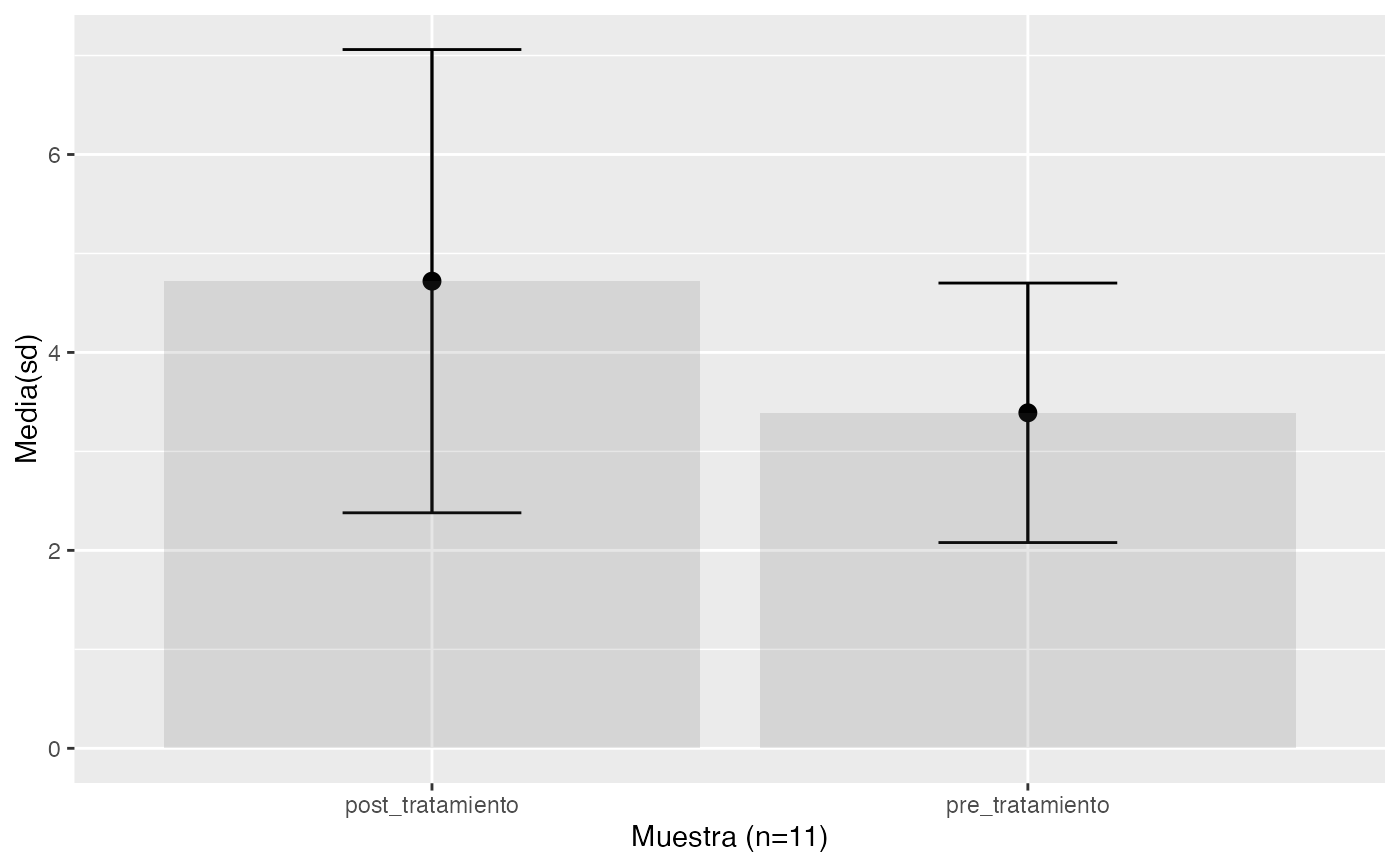
 #>
# [C.2] 2 muestras apareadas con datos sintetizados (es el test con una sola
# muestra, habitualmente m0=0)
testt(m=0.65, s=1.2, n=17)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 17.000
#> media = 0.650
#> d.t. = 1.200
#> sem = 0.291
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (0.033, 1.267)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=0.000
#> texp = 2.233, gl = 16
#> p = 0.040 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.020 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ) = (0.033, 1.267)
# [D] Estudio de la fiabilidad por H0 y estimacion del tamano de muestra (basta
# anadir el parametro delta a cualquiera de las opciones anteriores)
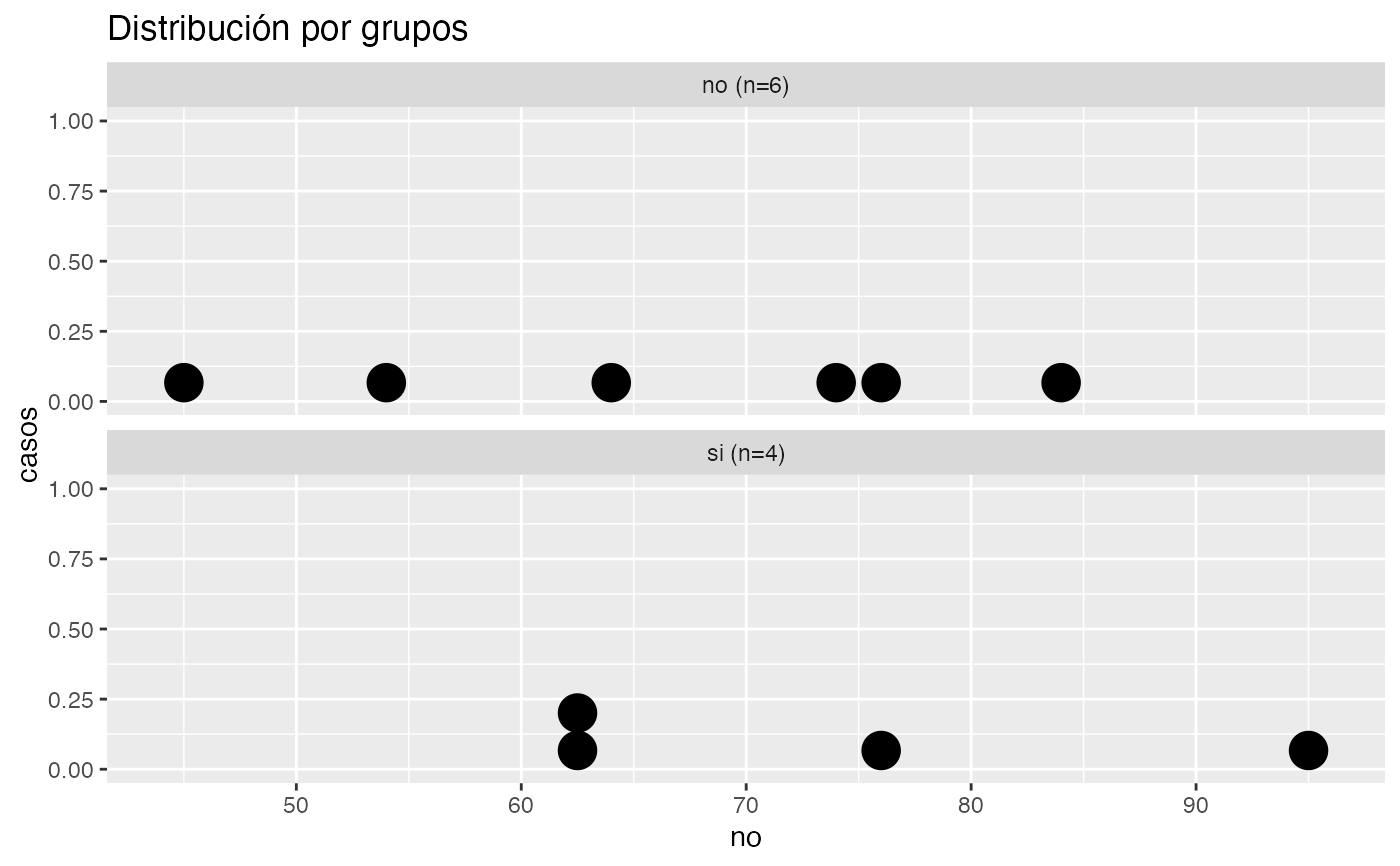
testt(m=peso, grupos=fuma, delta=5, potencia=0.95)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: no, si
#>
#> n media dt sem IC
#> peso [no] 6 67.667 13.604 5.554 (53.39, 81.943)
#> peso [si] 4 71.750 17.970 8.985 (43.156, 100.344)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = no, W = 0.947, gl = 6, p = 0.719
#> [2] Para grupo = si, W = 0.961, gl = 4, p = 0.783
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.745, gl₁ = 3, gl₂ = 5, p = 0.547
#>
#> # Diferencia de medias (peso [si] - peso [no])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 0.411, gl = 8
#> p = 0.692 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.346 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-18.821, 26.987)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 0.387, gl = 5.27
#> p = 0.714 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.357 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-22.658, 30.824)
#>
#> # Estudio de la potencia: δ = 5 -> [-5, 5], potencia θ =95%
#> 90%-IC(μ₂-μ₁) = (-16.964, 25.130)
#>
#> -(-[---|---]-)-- potencia < 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=5 con potencia θ=95%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 329 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.321, (gl'=6.89)
#> n₁ ⩾ 314 casos en el grupo [1]
#> n₂ ⩾ 415 casos en el grupo [2]
#>
#>
# [C.2] 2 muestras apareadas con datos sintetizados (es el test con una sola
# muestra, habitualmente m0=0)
testt(m=0.65, s=1.2, n=17)
#>
#> # t-Test con una muestra
#> # ----------------------
#>
#> # Resumen de 'Muestra'
#> n = 17.000
#> media = 0.650
#> d.t. = 1.200
#> sem = 0.291
#>
#> # Estimación de la media μ:
#> 95%-IC(μ) = (0.033, 1.267)
#>
#> # Test de Student para contrastar H₀:μ=μ₀ con μ₀=0.000
#> texp = 2.233, gl = 16
#> p = 0.040 para la alternativa bilateral H₁:μ≠μ₀
#> p = 0.020 para la alternativa unilateral H₁:μ>μ₀
#>
#> Estimación del efecto bruto
#> 95%-IC(μ) = (0.033, 1.267)
# [D] Estudio de la fiabilidad por H0 y estimacion del tamano de muestra (basta
# anadir el parametro delta a cualquiera de las opciones anteriores)
testt(m=peso, grupos=fuma, delta=5, potencia=0.95)
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: no, si
#>
#> n media dt sem IC
#> peso [no] 6 67.667 13.604 5.554 (53.39, 81.943)
#> peso [si] 4 71.750 17.970 8.985 (43.156, 100.344)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = no, W = 0.947, gl = 6, p = 0.719
#> [2] Para grupo = si, W = 0.961, gl = 4, p = 0.783
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 1.745, gl₁ = 3, gl₂ = 5, p = 0.547
#>
#> # Diferencia de medias (peso [si] - peso [no])
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 0.411, gl = 8
#> p = 0.692 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.346 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-18.821, 26.987)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 0.387, gl = 5.27
#> p = 0.714 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.357 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-22.658, 30.824)
#>
#> # Estudio de la potencia: δ = 5 -> [-5, 5], potencia θ =95%
#> 90%-IC(μ₂-μ₁) = (-16.964, 25.130)
#>
#> -(-[---|---]-)-- potencia < 95%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=5 con potencia θ=95%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 329 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.321, (gl'=6.89)
#> n₁ ⩾ 314 casos en el grupo [1]
#> n₂ ⩾ 415 casos en el grupo [2]
#>

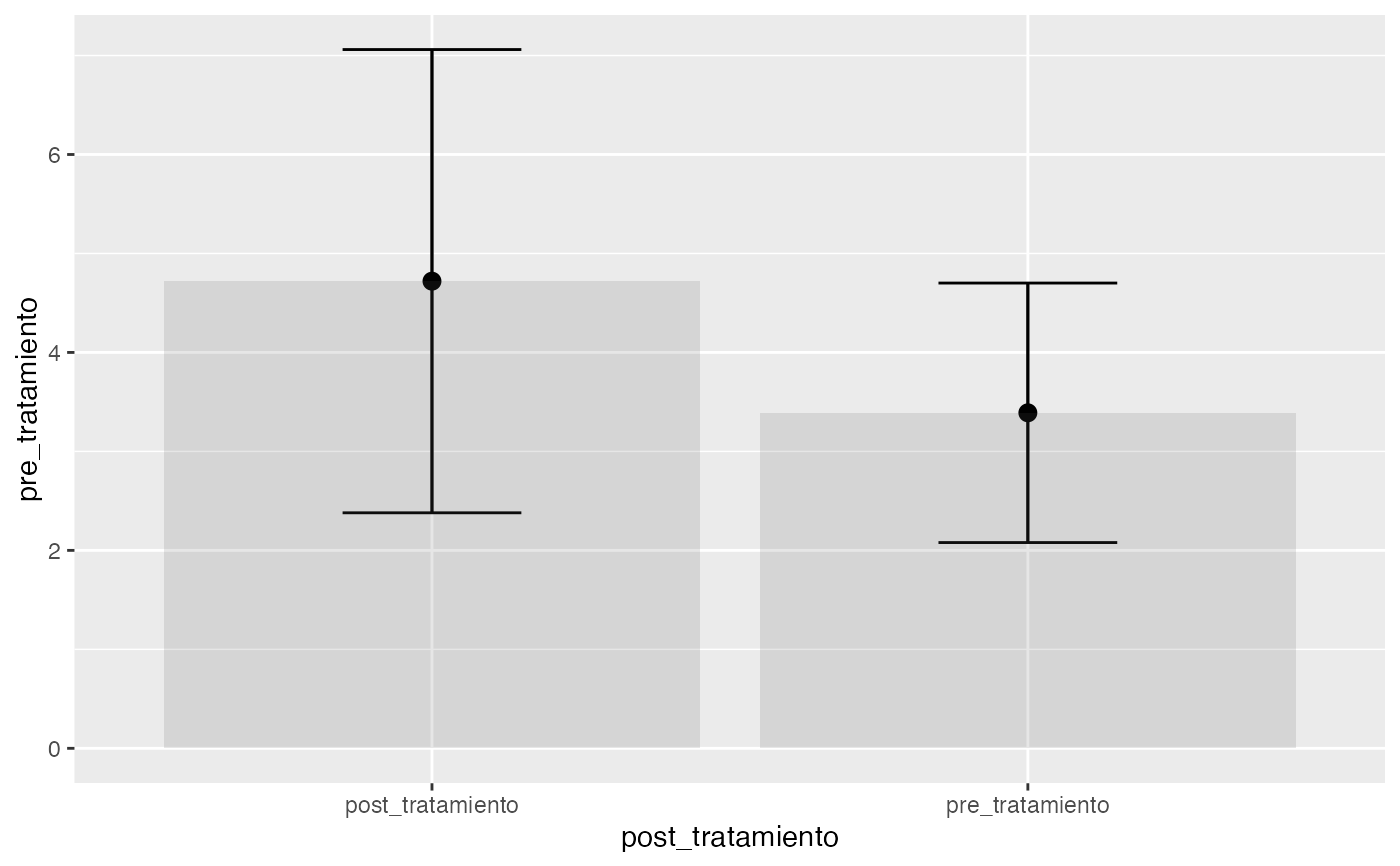
 testt(m1=pre_tratamiento, m2=post_tratamiento, delta=0.5, potencia=0.85)
#>
#> [!] Las muestras pre_tratamiento y post_tratamiento tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#>
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: pre_tratamiento, post_tratamiento
#>
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = pre_tratamiento, W = 0.909, gl = 10, p = 0.277
#> [2] Para grupo = post_tratamiento, W = 0.890, gl = 10, p = 0.169
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.187, gl₁ = 9, gl₂ = 9, p = 0.099
#>
#> # Diferencia de medias (post_tratamiento - pre_tratamiento)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 1.568, gl = 18
#> p = 0.134 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.067 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.452, 3.112)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 1.568, gl = 14.14
#> p = 0.139 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.070 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.488, 3.148)
#>
#> # Estudio de la potencia: δ = 0.5 -> [-0.5, 0.5], potencia θ =85%
#> 70%-IC(μ₂-μ₁) = (0.417, 2.243)
#>
#> ---[---|-(-]-)-- potencia < 85%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=0.5 con potencia θ=85%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 289 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.785, (gl'=16.67)
#> n₁ ⩾ 194 casos en el grupo [1]
#> n₂ ⩾ 347 casos en el grupo [2]
#>
testt(m1=pre_tratamiento, m2=post_tratamiento, delta=0.5, potencia=0.85)
#>
#> [!] Las muestras pre_tratamiento y post_tratamiento tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#>
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: pre_tratamiento, post_tratamiento
#>
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = pre_tratamiento, W = 0.909, gl = 10, p = 0.277
#> [2] Para grupo = post_tratamiento, W = 0.890, gl = 10, p = 0.169
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.187, gl₁ = 9, gl₂ = 9, p = 0.099
#>
#> # Diferencia de medias (post_tratamiento - pre_tratamiento)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 1.568, gl = 18
#> p = 0.134 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.067 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.452, 3.112)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 1.568, gl = 14.14
#> p = 0.139 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.070 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.488, 3.148)
#>
#> # Estudio de la potencia: δ = 0.5 -> [-0.5, 0.5], potencia θ =85%
#> 70%-IC(μ₂-μ₁) = (0.417, 2.243)
#>
#> ---[---|-(-]-)-- potencia < 85%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=0.5 con potencia θ=85%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 289 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.785, (gl'=16.67)
#> n₁ ⩾ 194 casos en el grupo [1]
#> n₂ ⩾ 347 casos en el grupo [2]
#>
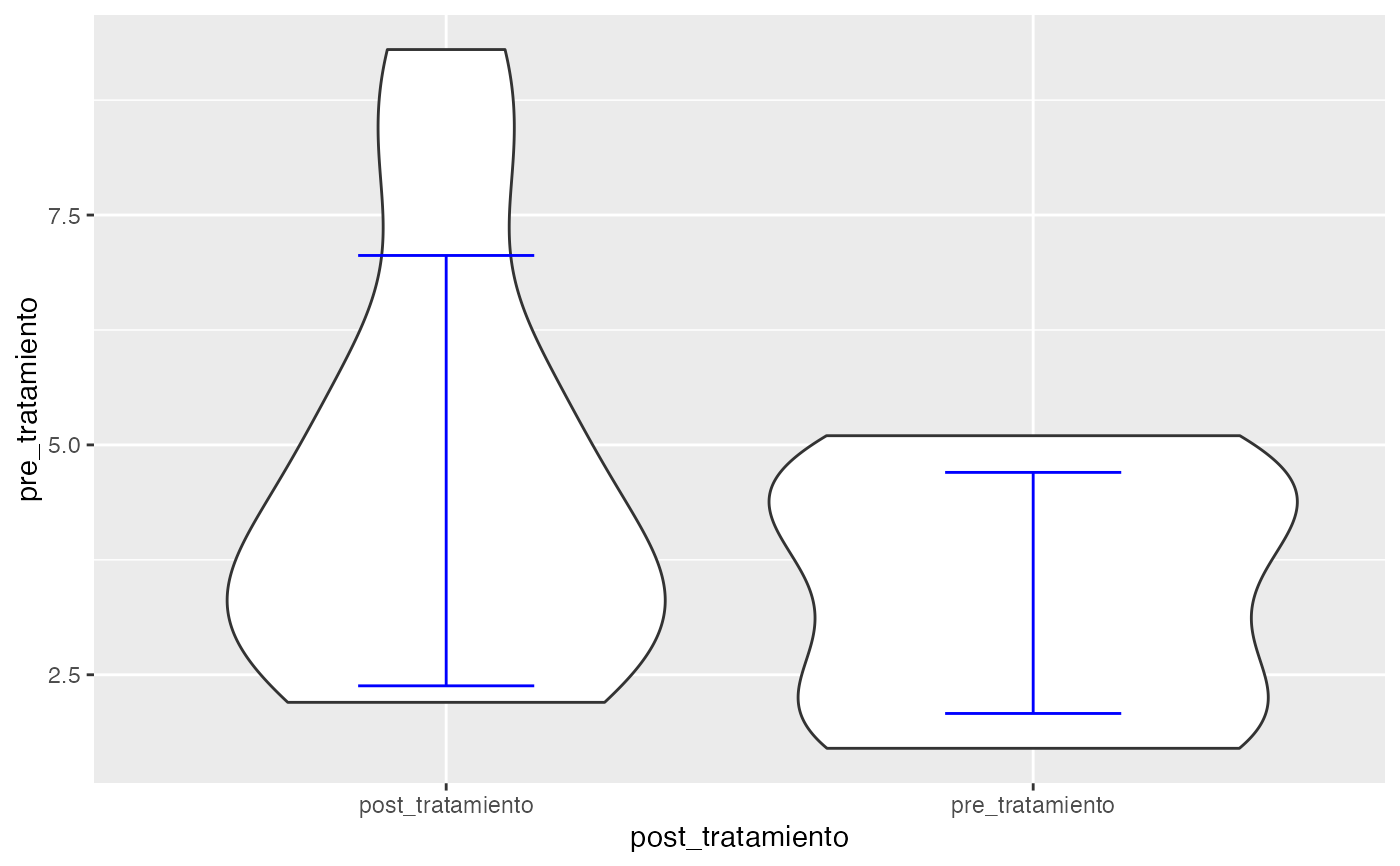
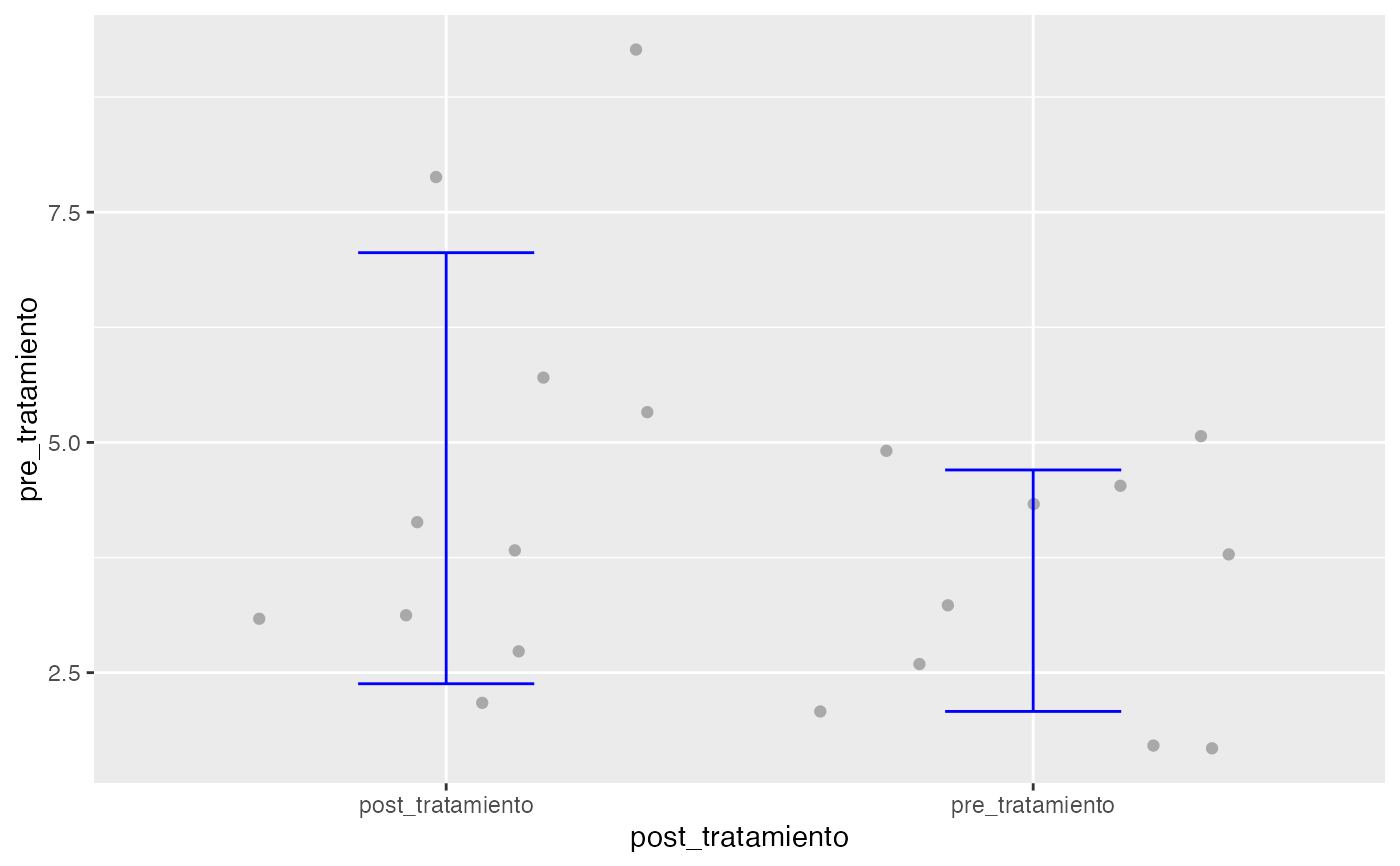
 testt(m1=pre_tratamiento, m2=post_tratamiento, delta=0.5, beta=0.15)
#>
#> [!] Las muestras pre_tratamiento y post_tratamiento tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#>
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: pre_tratamiento, post_tratamiento
#>
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = pre_tratamiento, W = 0.909, gl = 10, p = 0.277
#> [2] Para grupo = post_tratamiento, W = 0.890, gl = 10, p = 0.169
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.187, gl₁ = 9, gl₂ = 9, p = 0.099
#>
#> # Diferencia de medias (post_tratamiento - pre_tratamiento)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 1.568, gl = 18
#> p = 0.134 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.067 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.452, 3.112)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 1.568, gl = 14.14
#> p = 0.139 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.070 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.488, 3.148)
#>
#> # Estudio de la potencia: δ = 0.5 -> [-0.5, 0.5], potencia θ =85%
#> 70%-IC(μ₂-μ₁) = (0.417, 2.243)
#>
#> ---[---|-(-]-)-- potencia < 85%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=0.5 con potencia θ=85%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 289 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.785, (gl'=16.67)
#> n₁ ⩾ 194 casos en el grupo [1]
#> n₂ ⩾ 347 casos en el grupo [2]
#>
testt(m1=pre_tratamiento, m2=post_tratamiento, delta=0.5, beta=0.15)
#>
#> [!] Las muestras pre_tratamiento y post_tratamiento tienen el mismo tamaño, pero no se ha indicado
#> par=TRUE. Se asume que las muestras son independientes.
#>
#>
#> # t-test para 2 Muestras Independientes
#> # -------------------------------------
#>
#> [!] Aparecen datos faltantes en pre_tratamiento
#> Aparecen datos faltantes en post_tratamiento
#>
#>
#> # Información muestral y estimación de las medias
#> Niveles de agrupación: pre_tratamiento, post_tratamiento
#>
#> n nmiss media dt sem IC
#> pre_tratamiento 10 1 3.39 1.311 0.415 (2.452, 4.328)
#> post_tratamiento 10 1 4.72 2.340 0.740 (3.046, 6.394)
#> ____
#> * IC elaborados al 95% de confianza para estimar μ₁ y μ₂ respectivamente
#> **En el recuento n ya se han excluido los valores faltantes
#>
#>
#> # Pruebas de normalidad (test de Shapiro-Wilk)
#> [1] Para grupo = pre_tratamiento, W = 0.909, gl = 10, p = 0.277
#> [2] Para grupo = post_tratamiento, W = 0.890, gl = 10, p = 0.169
#>
#> # Test de homogeneidad de varianzas. Fexp = (var₂/var₁)
#> Fexp = 3.187, gl₁ = 9, gl₂ = 9, p = 0.099
#>
#> # Diferencia de medias (post_tratamiento - pre_tratamiento)
#> Hipótesis a contrastar: H₀:μ₁=μ₂ (μ₂-μ₁=0)
#>
#> a) Test de Student (varianzas homogéneas)
#> texp = 1.568, gl = 18
#> p = 0.134 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.067 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.452, 3.112)
#>
#> b) Test de Welch (varianzas no homogéneas)
#> texp = 1.568, gl = 14.14
#> p = 0.139 para la alternativa bilateral H₁:μ₁≠μ₂
#> p = 0.070 para la alternativa unilateral H₁:μ₁<μ₂
#> 95%-IC(μ₂-μ₁) = (-0.488, 3.148)
#>
#> # Estudio de la potencia: δ = 0.5 -> [-0.5, 0.5], potencia θ =85%
#> 70%-IC(μ₂-μ₁) = (0.417, 2.243)
#>
#> ---[---|-(-]-)-- potencia < 85%
#>
#> Leyenda: --(---)-- --[---|---]--
#> IC- IC+ -δ 0 +δ
#>
#> # Estimación del tamaño muestral para detectar una diferencia δ=0.5 con potencia θ=85%
#> (1) Considerando las varianzas homogéneas:
#> (n1 = n2) ⩾ 289 casos en cada grupo
#>
#> (2) Considerando las varianzas heterogéneas: k=s₂/s₁=1.785, (gl'=16.67)
#> n₁ ⩾ 194 casos en el grupo [1]
#> n₂ ⩾ 347 casos en el grupo [2]
#>